
NumPy、Pandas、python绘图、FastAPI
b站python基础学习笔记
目录
b站python基础学习笔记
vs code中配置python虚拟环境
可参考教程:vscode使用python虚拟环境配置详解_哔哩哔哩_bilibili

注:关于vscode中ipynb选择内核时找不到内核(输入路径也不行)的问题解决
更新下jupyter(可更改为预发布版本),再重启vscode就可以选择到内核了
参考:关于vscode连接服务器后运行ipynb文件要求选择“....ipynb“的内核时找不到任何可用的内核的解决方案 - 知乎
以下教程来自b站
一、NumPy
1.概念
- 线性代数工具包,用于基本的线性代数和数值计算
- 主要用于处理大规模的数组和矩阵数据,以及对这些数据执行各种数学运算
- 许多高级包的依赖基础,如pytorch(神经网络)、pandas(数据处理)
- 底层是C实现,在CPU上做了优化,效率很高
- NumPy核心:ndarray、矢量化运算、广播机制
2.数值文件的读写
实验室数据常以文件存储(乃至于数据库),读写方法:二进制文件、文本文件
- 文本文件: .txt 和 .csv文件
- 二进制文件: .npy文件 (速度快)
numpy 读写文件的两种方法
#对 txt,csv的文本文件读写
np.savetxt('array.csv',arr,delimiter=',')
np.loadtxt('array.csv',delimiter=',')
#对 npy 的二进制文件读写
np.save('array.npy',arr)
np.load('arry.npy')3.ndarray类型
概念:ndarray(n dimensional array)(n维数组),一种numpy数组的实现,支持更多的数学运算
- numpy包主要操作对象是ndarray类型的对象,而array是它的一个“从python list 创建 ndarray"的方法
np.array 注意这是个函数 # Callable [ [ list ] , np.ndarray ]
np.ndarray 注意这是个类型 #class
- 其中 Callable [ [ list ] , np.ndarray ] 表达的是,在numpy的源文件中,array()很可能是这样编写的:
def array(args: list) -> ndarray: #传入的参数args是list类型
...
return result: ndarray
#array()函数的作用:把python的list转换成numpy的ndarray类型
#涉及类型标注,让项目更严谨,类型出错时候会提醒报错总结:从类型上看,ndarray和np.array并不是一回事
二、Pandas
1.概念
- 数据分析工具,核心代码是用cython和c编写,灵活易用高效
- pandas(衍生自panel data) :高性能、易用的数据分析包,提供易于使用的数据结构和数据分析工具,特别适合处理表格型数据(如excel\数据库表等)
- pandas的两个核心数据类型:series、DataFrame
- 相对于数据库,pandas适用于中小型数据,其crud(creat、read、update、delete)与db(数据库)大致相同
- 使用时数据是存在内存上的,使用时需要注意否则数据量太大会导致电脑卡死
2.一维数据结构Series
Series:具有索引的一维数组的结构,每个数据项都可以通过标签访问
Series示例:
import pandas as pd
#从列表创建series
s1=pd.Seires([10,20,30,40],index=['a','b','c','d'])
#从字典创建
s2=pd.Series({'a':10,'b':20,'c':30,'d':40})
print("s1['a']:",s1['a'])
print("s2['b']:",s2['b'])output
s1['a']: 10
s2['b']: 20
3.二维数据结构 DataFrame
DataFrame:一个二维表格型的数据结构。可以理解为一个表格,每一行每一列都有自己的标签(索引和列名)
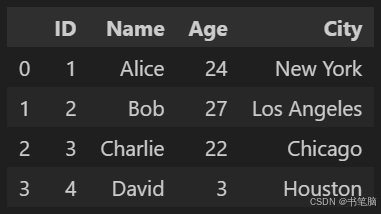
DataFrame
# 从二维列表创建 DataFrame
data1 = [
[1, 'Alice', 24, 'New York'],
[2, 'Bob', 27, 'Los Angeles'],
[3, 'Charlie', 22, 'Chicago'],
[4, 'David', 3, 'Houston']
]
df1 = pd.DataFrame(data1, columns=['ID', 'Name', 'Age', 'City']) # 不指定columns默认为从0递增的序列# 从字典创建 DataFrame
data2 = {
'ID': [1, 2, 3, 4],
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [24, 27, 22, 32],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston']
}
df2 = pd.DataFrame(data2)output
4.DataFrame的常用操作
1)文件读写:分为csv和excel文件两种
#csv
df=pd.read_csv('sample_data.csv',sep=',')
df.to_csv('output.csv',index=False)
#excel
df=pd.read_excel('sample_data.xlsx')
df.to_excel('output.xlsx')2)修改操作
pandas的设计中,具有修改的操作通常会有inplace参数,默认是False,即不会修改原数据,而是返回一个新的对象,故如果inplace为false时,需要用一个新的变量接住新的对象。inplace参数
#inplace=True时,修改的数据会覆盖原数据
df.drop('column1',axis=1,inplace=True)#删除一列
#如果inplace为false,不会修改原数据,需要用一个新的变量接住这个修改,如下
a=df.drop('column1',axis=1,inplace=False)3)查看DataFrame的数据信息 常用的数据索引方式:多行/列索引、条件索引
#多行/列索引
df.loc[2:4,'columnl'] #假设行标签是2到4,选择名称为columnl的列(location通过标签名称来定位)
df.iloc[2:4,7] # 2到3行,选择第8列(int location通过编号来定位)
# 多列
print(df[['年龄', '成绩']]) # 选择多个列
#条件索引
df[df['columnl']>10] #列值大于10的行
df[(df['age']>30)&(df['score']>300)] #要用位运算操作符,不能用and4)常用的数据统计方法
import pandas as pd
data = {
'姓名': ['张三', '李四', '王五', '赵六', '钱七', '孙八', '周九', '吴十', '郑十一', '马十二'],
'年龄': [18, 19, 20, 21, 22, 23, 24, 25, 26, 27],
'成绩': [85, 92, 78, 89, 95, 87, 90, 93, 80, 88]
}
df = pd.DataFrame(data)
# 计数
df['年龄'].count() # 计算column1中的非空值数量
# 众数
df['年龄'].mode() # 找出column1中的众数
# 最值
df['年龄'].min() # 计算column1的最小值
df['年龄'].max() # 计算column1的最大值
# 四分位点
df['成绩'].quantile(0.25) # 计算column1的第25百分位数
# 求和/均值
df['成绩'].sum() # 计算column1的和
df['成绩'].mean() # 计算column1的平均值
# 标准差/方差
df['成绩'].std() # 计算column1的标准差
df['成绩'].var() # 计算column1的方差5)常用的数据处理操作
import pandas as pd
data = {
'姓名': ['张三', '李四', '王五', '赵六', '钱七', '孙八', '周九', '吴十', '郑十一', '马十二'],
'年龄': [18, 19, 20, 21, 22, 23, 24, 25, 26, 27],
'成绩': [85, 92, 78, 89, 95, 87, 90, 93, 80, 88]
}
df = pd.DataFrame(data)
# 增
df.loc[5] = ['Tom', 25, 90] #
df['总成绩'] = df['成绩'] # 新增一列
# 删
df.drop('总成绩', axis=1, inplace=True) # 删除一列
df.drop(0, axis=0, inplace=True) # 删除第一行
# 改
df.at[0, '成绩'] = 10 # 修改特定单元格的值
df['成绩'] = df['成绩'].replace(10, 20) # 将column1中的10替换为20
# 批量处理
df.apply(lambda x: x * 2, axis=0) # axis=0按列处理,axis=1按行处理
# 重命名
df.rename(columns={'年龄': '生理年龄'}, inplace=True) # 重命名列
df.rename(index={0: 12}, inplace=True) # 重命名行
# 缺失值处理
df.dropna() # 删除包含缺失值的行
df.fillna(0) # 将缺失值填充为0
df.fillna({'成绩': df['成绩'].mean()}, inplace=True) # 用平均值填充缺失值
# 去重
df.drop_duplicates(inplace=True) # 删除重复行
# 排序
df.sort_values(by='成绩', ascending=True) # 按column1升序排序
df.sort_index(axis=0, ascending=False) # 按行索引降序排序
# 分组
df.groupby('成绩').sum() # 按column1分组并求和
df.groupby(['成绩', '生理年龄']) # 按多个列分组
for (name, gp) in df.groupby('成绩'): # 分组遍历
pass
df = pd.DataFrame(data)
# 合并
pd.merge(df, df, on='成绩') # 基于“key”列合并两个DataFrame
pd.concat([df, df], axis=0) # 在行上合并
pd.concat([df, df], axis=1) # 在列上合并
# 可视化
df['成绩'].plot(kind='line') # 折线图
df.plot(kind='bar') # 柱状图
df.plot(kind='scatter', x='成绩', y='年龄') # 散点图三、Python绘图
matplotlib、plotly、pyecharts
参考教程:05 python 绘图_哔哩哔哩_bilibili
1.Matplotlib
Matplotlib是目前最流行和广泛使用的python绘图模块,import as plt
特点:
- 灵活、可以更好控制细节,比如纸条样式、颜色等
- 社区活跃,文档完善
适用场景:
- 科学研究和数据分析中的图表制作
- 需要高度定制化图形的应用
编码模式:
- 用 plt.figure() 创建Figure对象
- 用 plt.{any}chart() 传入数据绘制具体的{any}图表
- 用 plt.{any}seter() 调节图表的参数和布局
- 用 plt.show() 显示图表或者 plt.savefig() 保存图表
注意: plt的操作对象是图,如果不指明操作对象,那么操作的是全局的默认图,如果有多张图,全局默认操作最后一张图。
另:Seaborn同样也是很流行的科学图表制作模块,其对matplotlib进行了一层封装,提供了更简洁的接口和更美观的默认样式,具体的编码模式与matplotlib相同
import matplotlib.pyplot as plt
# 示例数据:一个月内每天的销售量
days = list(range(1, 31)) # 1到30天
sales = [250, 300, 280, 310, 290, 330, 340, 360, 300, 310,
280, 350, 360, 390, 370, 400, 420, 430, 410, 390,
400, 420, 430, 440, 450, 460, 480, 500, 490, 520]
# 创建图形对象
plt.figure(figsize=(10, 6))
# 绘制柱状图
plt.bar(days, sales, color='lightblue', alpha=0.7, label='Daily Sales')
# 绘制折线图
plt.plot(days, sales, color='blue', marker='o', linestyle='-', label='Trend')
# 添加标题和标签
plt.title('Daily Sales for a Month')
plt.xlabel('Day')
plt.ylabel('Sales')
plt.legend()
# 显示图形
plt.show()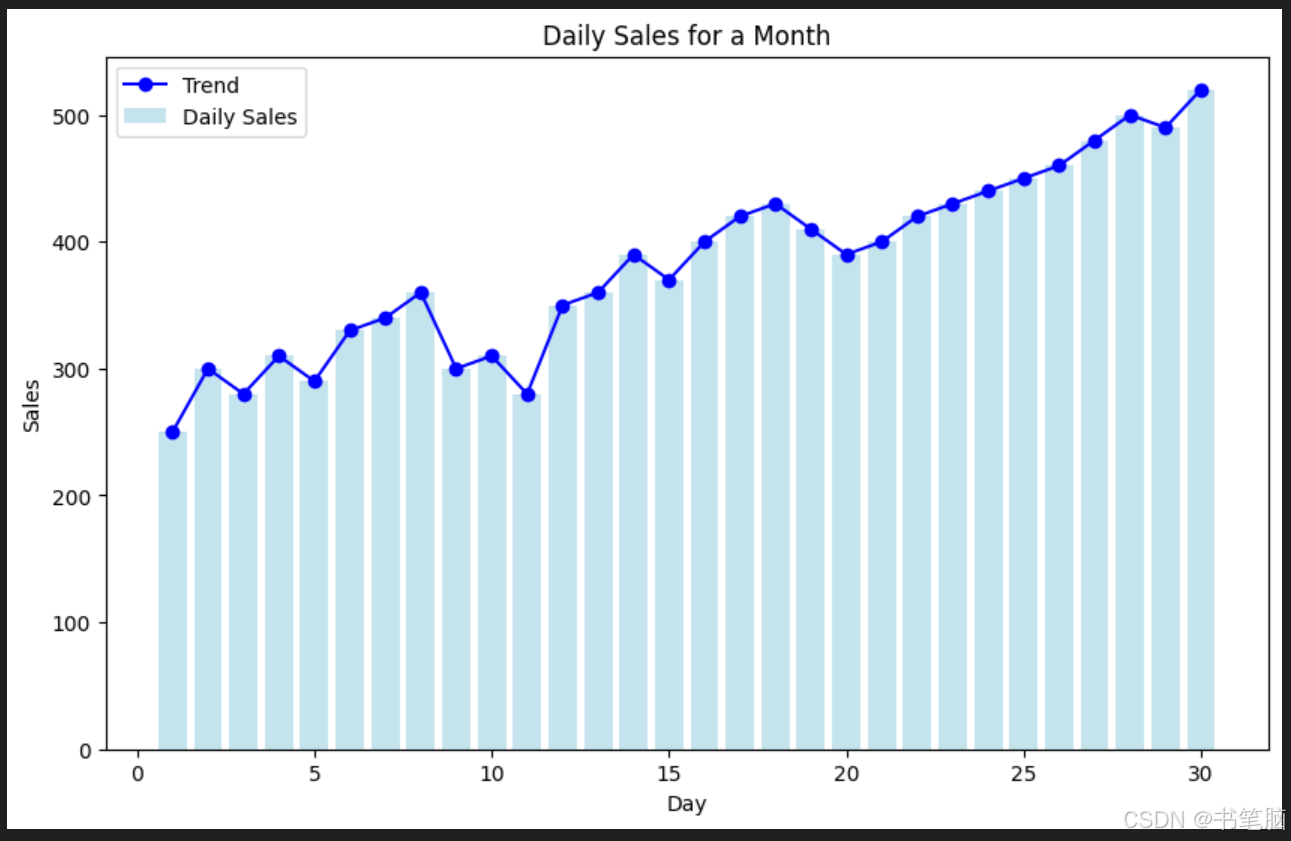
2.Plotly
plotly是一个交互可视化工具,支持创建交互式的图表,如缩放、平移等操作
特点:
- 提供了丰富的交互功能
- 能够在线分享图表
适用场景:需要用户交互的数据展示
编码模式:
- 用 chart=go.{any}chart() 传入数据绘制具体的{any}图表 (建个chart图表接住数据)
- 用 fig=go.Figure(data=[chart]) 创建Figure对象并将图表渲染到Figure上(建个图像figure)
- 用 fig.update_layout() 设置图表的参数和布局
- 用 fig.show() 显示图表或者 fig.write.image() 保存图表
import plotly.graph_objects as go
# 示例数据:一个月内每天的销售量
days = list(range(1, 31))
sales = [250, 300, 280, 310, 290, 330, 340, 360, 300, 310,
280, 350, 360, 390, 370, 400, 420, 430, 410, 390,
400, 420, 430, 440, 450, 460, 480, 500, 490, 520]
# 创建柱状图
bar = go.Bar(
x=days,
y=sales,
name='Daily Sales',
marker=dict(color='lightblue'),
opacity=0.7
)
# 创建折线图
line = go.Scatter(
x=days,
y=sales,
mode='lines+markers',
name='Trend',
marker=dict(color='blue')
)
# 创建图形对象
fig = go.Figure(data=[bar, line])
# 添加标题和标签
fig.update_layout(
title='Daily Sales for a Month',
xaxis_title='Day',
yaxis_title='Sales',
legend_title='Legend'
)
# 显示图形
fig.show() 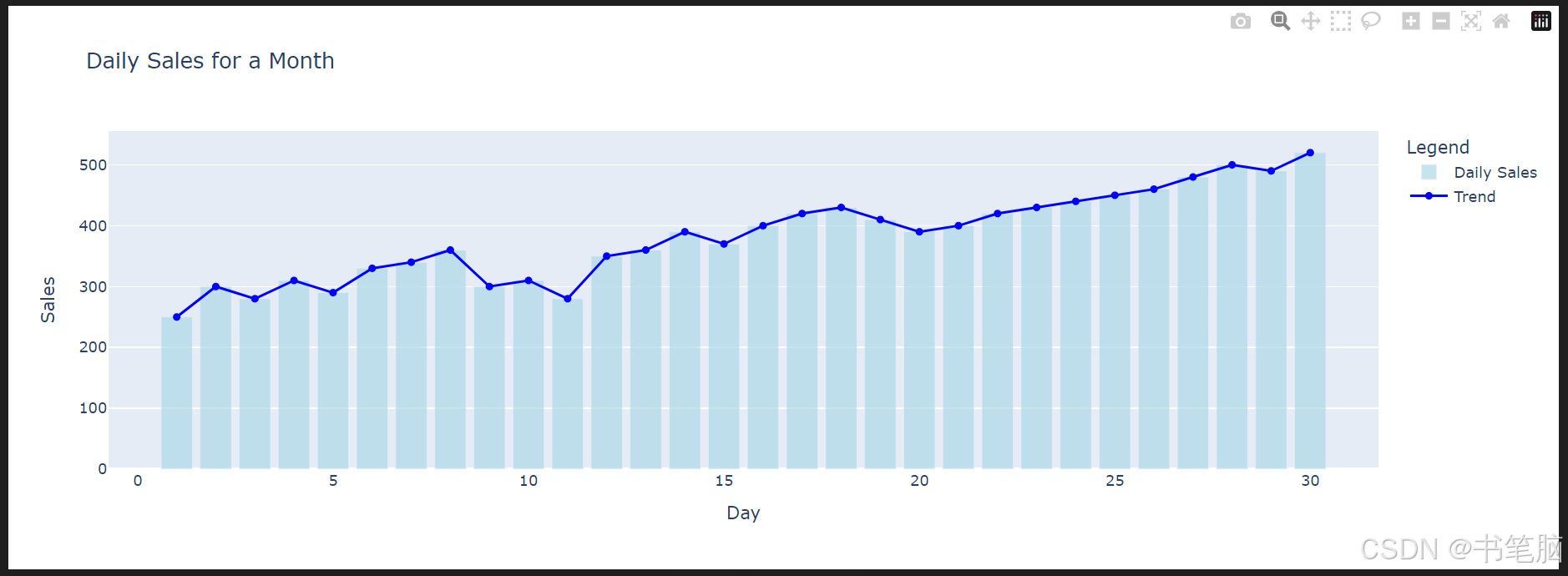
图表可以交互,如框选放大,或者鼠标放到折线点会显示数值
3.PyEcharts
PyEcharts 是一个基于 ECharts 的 Python 库,ECharts 是百度推出的一个纯 JavaScript 的图表库。
特点:
- 强大的图表类型支持
- 与Echarts无缝集成
- 自动生成HTML文件
适用场景:
- Web开发中的数据可视化
- 需要用户交互的数据展示
- 与JavaScript的集成
编码模式:
- 用 chart=chart()根据传入数据绘制具体的{any}图表
- 针对chart进行额外的设置
- 用 chart.render()导出为html文件 或chart.render_notebook() 直接在jupyter notebook中显示 (render渲染器的意思)
rom pyecharts.charts import Bar, Line
from pyecharts import options as opts
# 示例数据:一个月内每天的销售量
days = list(range(1, 31))
sales = [250, 300, 280, 310, 290, 330, 340, 360, 300, 310,
280, 350, 360, 390, 370, 400, 420, 430, 410, 390,
400, 420, 430, 440, 450, 460, 480, 500, 490, 520]
# 创建柱状图
bar = (
Bar()
.add_xaxis(days)
.add_yaxis("Daily Sales", sales, color="lightblue")
.set_global_opts(
title_opts=opts.TitleOpts(title="Daily Sales for a Month"),
xaxis_opts=opts.AxisOpts(name="Day"),
yaxis_opts=opts.AxisOpts(name="Sales"),
legend_opts=opts.LegendOpts(pos_top="5%")
)
)
# 创建折线图
line = (
Line()
.add_xaxis(days)
.add_yaxis("Trend", sales, is_smooth=True, linestyle_opts=opts.LineStyleOpts(color="blue"))
)
# 将两个图表结合到一起
bar.overlap(line)
# 显示图形
bar.render_notebook()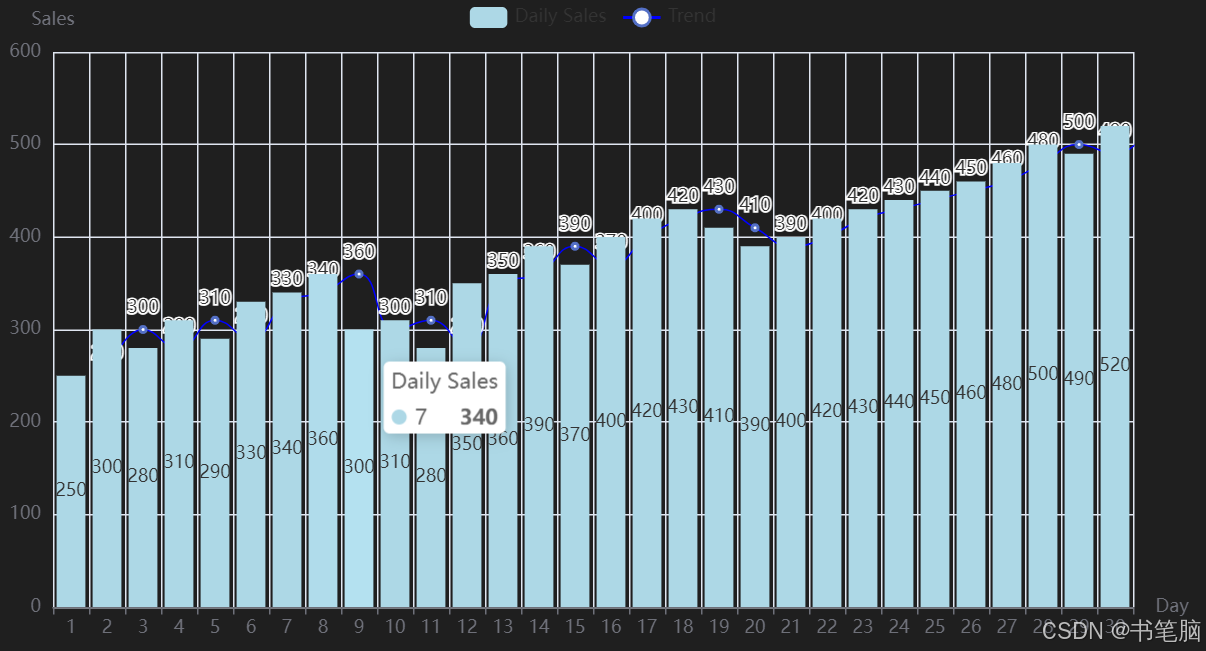
图表可交互
总结
通常在绘图的时候都会是这样的流程:
- 准备数据
- 使用第三方模块将数据绘制成图
- 调整图的参数和布局
- 显示或者保存绘制好的图像
三个库的选择简单来说:
- 如果你需要的是一个简单但强大的绘图工具,可以选择 Matplotlib
- 如果你希望创建交互式的图表,可以选择 Plotly
- 而如果你正在开发 Web 应用并且想要快速集成图表,可以选择 PyEcharts
四、FastAPI
FastAPI![]() https://fastapi.tiangolo.com/zh/FastAPI 是一个用于构建 API 的现代、快速(高性能)的 web 框架,使用 Python 并基于标准的 Python 类型提示。
https://fastapi.tiangolo.com/zh/FastAPI 是一个用于构建 API 的现代、快速(高性能)的 web 框架,使用 Python 并基于标准的 Python 类型提示。
FastAPI项目
- 工具、项目结构、app与服务
工具:
- FastAPI 包和 uvicorn 包
pip install fastapi pip install "uvicorn[standard]"uvicorn 是一个后端框架无关的(不用fastapi,换别的后端框架,还是可用用uvicon启动),用于启动 HTTP 服务的工具
也就是说,你需用 Uvicorn 来运行你的 FastAPI 应用
项目结构:
一个典型的 FastAPI 项目应该包含以下文件结构:
fastapi_project/
├── app/
│ ├── __init__.py
│ ├── main.py # 主应用程序入口
│ ├── api/ # API 路由
│ │ ├── __init__.py
│ │ └── endpoints/ # 具体的 API 端点
│ ├── models/ # 数据模型
│ ├── schemas/ # Pydantic 模式
│ ├── services/ # 业务逻辑层
│ └── database/ # 数据库连接与管理
│
├── tests/ # 测试文件,正规开发会用到
│ ├── __init__.py
│ └── test_main.py # 主要测试文件
│
├── requirements.txt # 项目依赖,用 pip-install -r requirements.txt 来进行
装包
└── README.md # 项目说明文件
app与服务:
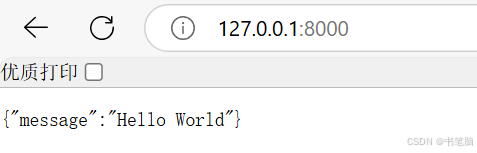
from fastapi import FastAPI app=FastAPI() @app.get("/") async def root(): return {"meaasge":,"Hello World"}基础FastAPI应用,请查看main.py(教程up主给的学习文件)
- @app.get : python 的装饰器,用于定义路由。用装饰器修饰的函数会被处理一次。这里的处理指将函数注册到 app 的路由表中
- async 用于异步操作,几乎所有网络相关的操作都是异步的。详情见 public 编程语言 language 和 网络 network 部分。
uvicorn {入口文件名}:app --reload注意:
- 如果没加--reload,你在py文件中的修改并不会实时更新,还处于更改前的项目,要更新只能先通过 ctrl+c 强行打断该项目,然后重新加载新项目
- 加了--reload就可以实施更新,改后记得ctrl+s,再去刷新网页就可以更新
以上案例说明了,当配置了 app 最基础的部分后(大部分配置都可以通过对app进行设置实现),我们可以通过访问服务器根路由/ 来得到文本“Hello World”。这就是用 FastAPI 开发的最简单的基于 HTTP 的后端服务(server)应用。
注意:
- 所有后端框架在开发中,测试运行时的ip通常是localhost(也即127.0.0.1,本机ip地址),FastAPI端口的配置默认是8000,也可以手动配置
- 大部分配置都可以通过对app进行设置实现
运行时出现的问题:
Error loading ASGI app. Could not import module "main".
解决方法:请在文件名前面添加文件夹名


路由
以某站为例:
xxx.com/ # 首页
xxx.com/about # 关于页
xxx.com/about/team # 团队页
xxx.com/login # 登录页
xxx.com/user/:username # 用户页
xxx.com/video/:id # 视频页
xxx.com/search?keyword=value # 搜索页
其中:xxx.com 是网站的域名,后面的部分称为“路由”(route )
- /about 、/about/team 为一级、二级路由。中文常作相关/关于页用于展示网站、网站团队的静态图文信息
- /login 为登录页,在输入用户名密码通过登录验证后,服务器将返回给客户端(浏览器,在用户机器上)一个 token(凭证),以便用户在后续访问时验证身份。token 常用浏览器 cookie 来存储
- cookie:一种在用户浏览器上存储少量数据的技术。本质是临时文件
- /user 为用户页,用于展示用户的个人信息。其中:username 部分为动态路由,意味着/user 后面可以跟任意的用户名(在地址栏中任何符合该格式的链接都能被匹配识别到该路由,而非其它路由上)。显然,不同用户访问某用户页时,分为本人和非本人两种情况,它们的操作逻辑也分为查看他人信息与查看和修改本人信息。他人和本人通过登陆后获取的 token 来区分
- /video 为视频页,用于展示视频内容。其中:id 部分为动态路由,意味着/video 后面可以跟任意的视频 ID
- /search 为搜索页,用于搜索关键字相关的内容。/search 跟随的是http的查询参数(以? 开头,由键值对key=value 来提供)
至此我们清楚了一般 Web 应用后端的需求:
- 根据 url 链接来处理内含的不同需求,并返回给客户端。
- 我们把处理这些需求的功能集中到一个进程,挂在在 server(服务器)上,称为 service(服务,对操作系统而言,区别于其它进程,一种进程类型)。
- url:统一资源定位符,以http:// 或https:// 开头(如 http://www.example.com)
- uri:统一资源标识符,以{example}: 开头(如 mysql://localhost/test)
- 两者都表现为链接
示例
from fastapi import FastAPI from pydantic import BaseModel # 创建一个FastAPI实例 app = FastAPI() # 根路由 @app.get("/") async def root(): """返回一个简单的欢迎信息。""" return {"message": "Hello World"} # 用户页面 - 使用路径参数 @app.get("/user/{username}") async def user_page(username: str): """根据提供的用户名返回用户信息。""" return f"the user's name is: {username}" # 搜索功能 - 使用查询参数 @app.get("/search") async def search(keyword: str = ""): """根据提供的关键词返回搜索结果。""" return f"用户搜索了关键词: {keyword}"根路由:
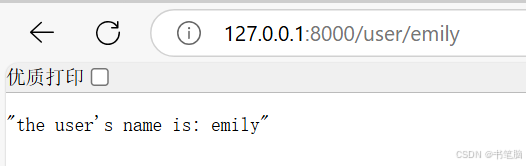
用户页面:
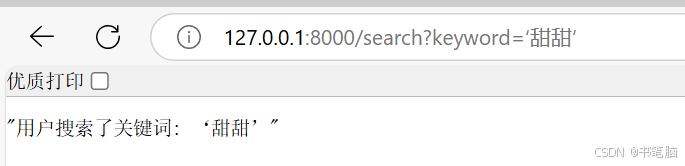
搜索功能:
路由的处理
通过 url 发送来的请求,做不同处理。可以认为处理路由就是后端业务的核心
路径参数(动态路由)
FastAPI 可以很方便地处理这种“动态网址”,我们只需要在路由中指定一个参数(比如 :username )。
比如对于 /user/:username
当用户访问 http://localhost:8000/user/emily 时,页面会显示“the user's name is: emily”。# 用户页面 - 使用路径参数 @app.get("/user/{username}") async def user_page(username: str): """根据提供的用户名返回用户信息。""" return f"the user's name is: {username}"
查询参数
比如在请求头的 URL 里添加 QueryParams(查询参数)。
查询字符串是键值对的集合,这些键值对位于 URL 的 ? 之后,以 & 分隔。
比如对于 /search?keyword=value
当用户访问 http://localhost:8000/search?keyword='google' 时,页面会显示“用户搜索了关键
词: google”。# 搜索功能 - 使用查询参数 @app.get("/search") async def search(keyword: str = ""): """根据提供的关键词返回搜索结果。""" return f"用户搜索了关键词: {keyword}"
body
- 上面我们一直用的是@app.get 装饰器,注册 GET 请求的路由。
- 对于 POST 请求,我们可以获取到请求体中的数据。
- 比如对于 /login
- 这里突然从@app.get 切换到@app.post 的理由,后续马上介绍
# 登录功能 - 使用POST请求体 @app.post("/login") async def login(form_data: LoginForm): """验证登录信息并返回相应的响应。""" if form_data.username == "admin" and form_data.password == "123456": # 如果用户名和密码正确,则返回登录成功的响应 token = {"status": "login", "username": form_data.username} return token else: return {"error": "用户名或密码错误"}
- 注意:token 往往是临时的,动态生成的,加密过后的。上述例子只是简化,记得用专门的token 生成用的加密方法(函数)。
- 当用户发送 POST 请求到 /login 时,我们能分情况返回登陆成功时的 token 或错误信息。
路由和报文的对应关系
一个典型的 HTTP 请求报文(Request)包含如下内容:

- HTTP method 常用的有 GET、POST(PUT、DELETE、HEAD、OPTIONS、TRACE)
- @app.get 明确了某路由下的特定类型(此处为 GET),同一路由可以有不同类型的请求。
- GET 和 POST 的选择依据是:GET 请求的信息往往放在 URL 里(HTTP 标准设计上 GET 不包含body),明文 URL 并不安全且信息量少(URL 长度限制);POST 请求的信息放在 body 里,信息量更大且安全性更高。
- 路径参数在请求信息的 URL 中
- 查询参数在请求信息的 URL 末尾,以? 开头,多个参数以& 分隔
- body 在请求体中,和其等价
五、必须知道的衍生
从文件分离,到路由分类集中
project文件夹(learning目录下(此为本人的学习笔记路径,详细笔记可去文章开头的b站链接up主那里找)
中间件
- 大致是讲如何在路由动作之前(或之后),统一加一个操作。这个被加在路由之前的操作,称为中间件(Middleware)
- 比如在每个路由上加一个 looger,记录每个请求的日志
- 具体查看文档
数据存储:从内存到数据库
内存存储
my_data = [] @app.post("/add_data") async def add_data(data: DataModel): my_data.append(dat当数据量过大时,改为数据库存储
db = DataBase.connect(...) @app.post("/add_data") async def add_data(data: DataModel): db.insert(db_data
六、-DB in FastAPI
- SQLite:轻量数据库
- SQLite3 是 SQLite 的一个稳定版本,内置于 Python 中
教程:07 DB in FastAPI 和 python 项目指导_哔哩哔哩_bilibili
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)