
Python科学计算 Pandas库
Pandas 是 Python 数据分析工具链中最核心的库,充当数据读取、清洗、分析、统计、输出的高效工具。是一个开源的数据分析和数据处理库,它是基于 Python 编程语言的。提供了易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据(类似于Excel表格)。是数据科学和分析领域中常用的工具之一,它使得用户能够轻松地从各种数据源中导入数据,并对数据进行高效的操作和分析。
目录
1、Pandas介绍
Pandas 是 Python 数据分析工具链中最核心的库,充当数据读取、清洗、分析、统计、输出的高效工具。
- 是一个开源的数据分析和数据处理库,它是基于 Python 编程语言的。
- 提供了易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据(类似于Excel表格)。
- 是数据科学和分析领域中常用的工具之一,它使得用户能够轻松地从各种数据源中导入数据,并对数据进行高效的操作和分析。
- Pandas是基于NumPy构建的专门为处理表格和混杂数据设计的Python库,其核心设计理念包括:
- 标签化数据结构:提供带标签的轴(行索引和列名)
- 灵活处理缺失数据:内置NaN处理机制
- 智能数据对齐:自动按标签对齐数据
- 强大IO工具:支持从CSV、Excel、SQL等20+数据源读写
- 时间序列处理:原生支持日期时间处理和频率转换
2、核心数据结构
Pandas 基于 Numpy,并提供了 2 大核心数据结构:
- Series:一维带有标签的数组
- DataFrame:二维表格结构,可看作多个 Series 的组合
用得最多的pandas对象是Series,一个一维的标签化数组对象,另一个是DataFrame,它是一个面向列的二维表结构。
|
特性 |
Series |
DataFrame |
|
维度 |
一维 |
二维 |
|
索引 |
单索引 |
行索引+列名 |
|
数据存储 |
同质化数据类型 |
各列可不同数据类型 |
|
类比 |
Excel单列 |
整张Excel工作表 |
|
创建方式 |
pd.Series([1,2,3]) |
pd.DataFrame({'col':[1,2,3]}) |
3、Series数据结构
(1)介绍
Series 是 Pandas 中的一个核心数据结构,类似于一个一维的数组,具有数据和索引。
Series 可以存储任何数据类型(整数、浮点数、字符串等),并通过标签(索引)来访问元素。Series 的数据结构是非常有用的,因为它可以处理各种数据类型,同时保持了高效的数据操作能力,比如可以通过标签来快速访问和操作数据。

(2)特点
- 一维数组:Series 中的每个元素都有一个对应的索引值。
- 索引: 每个数据元素都可以通过标签(索引)来访问,默认情况下索引是从 0 开始的整数,但你也可以自定义索引。
- 数据类型: Series 可以容纳不同数据类型的元素,包括整数、浮点数、字符串、Python 对象等。
- 大小不变性:Series 的大小在创建后是不变的,但可以通过某些操作(如 append 或 delete)来改变。
- 操作:Series 支持各种操作,如数学运算、统计分析、字符串处理等。
- 缺失数据:Series 可以包含缺失数据,Pandas 使用NaN(Not a Number)来表示缺失或无值。
- 自动对齐:当对多个 Series 进行运算时,Pandas 会自动根据索引对齐数据,这使得数据处理更加高效。
(3)创建
1)直接通过列表创建Series
arr = pd.Series([2, 4, 5, 7])
print('列表创建Series: ')
print(arr)
# 输出---------------------
列表创建Series:
0 2
1 4
2 5
3 7
dtype: int642)通过列表创建Series时指定索引
arr = pd.Series([2, 4, 5, 7], index=['a', 'b', 'c', 'd'])
print('列表创建Series指定索引: ')
print(arr)
# 输出----------------------------
列表创建Series指定索引:
a 2
b 4
c 5
d 7
dtype: int643)通过列表创建Series时指定索引和名称
arr = pd.Series([2, 4, 5, 7], index=['a', 'b', 'c', 'd'], name='Hello')
print('列表创建Series指定索引和名称: ')
print(arr)
# 输出--------------------------------------
列表创建Series指定索引和名称:
a 2
b 4
c 5
d 7
Name: Hello, dtype: int644)直接通过字典创建Series
arr = {'a':1, 'b':2, 'c':3}
arrpd = pd.Series(arr)
print('通过字典创建: ')
print(arrpd)
# 输出---------------------------
通过字典创建:
a 1
b 2
c 3
dtype: int645)获取一个新的Series
arr = {'a':1, 'b':2, 'c':3, 'd':4, 'e':5}
arrpd = pd.Series(arr)
print('通过字典创建: ')
print(arrpd)
print('----------------')
arr2 = pd.Series(arr, index=['b', 'd'], name='Hello')
print(arr2)
# 输出---------------------
通过字典创建:
a 1
b 2
c 3
d 4
e 5
dtype: int64
----------------
b 2
d 4
Name: Hello, dtype: int64(4)常用属性
|
属性 |
说明 |
|
index |
Series的索引对象 |
|
values |
Series的值 |
|
dtype或dtypes |
Series的元素类型 |
|
shape |
Series的形状 |
|
ndim |
Series的维度 |
|
size |
Series的元素个数 |
|
name |
Series的名称 |
|
loc[] |
显式索引,按标签索引或切片 |
|
iloc[] |
隐式索引,按位置索引或切片 |
|
at[] |
使用标签访问单个元素 |
|
iat[] |
使用位置访问单个元素 |
arr = pd.Series([1,2,3,4,5,6], index=['a','b','c','d','e','f'], name='month')
# 获取索引对象
print('索引值:', arr.index)
# 获取值
print('获取值: ', arr.values)
# 元素类型
print('元素类型: ', arr.dtype)
# 形状
print('形状: ', arr.shape)
# 维度
print('维度: ', arr.ndim)
# 元素个数
print('元素个数: ', arr.size)
# 名称
print('名称: ', arr.name)
# 显式索引
print('显式索引: ', arr.loc['a'])
print('显式索引: ', arr.loc['a' : 'c'])
# 隐式索引
print('隐式索引: ', arr.iloc[1])
print('隐式索引: ', arr.iloc[1 : 3])
# 标签访问
print('标签访问: ', arr.at['a'])
# 位置访问
print('位置访问: ', arr.iat[1])
# 输出----------------------------------
索引值: Index(['a', 'b', 'c', 'd', 'e', 'f'], dtype='object')
获取值: [1 2 3 4 5 6]
元素类型: int64
形状: (6,)
维度: 1
元素个数: 6
名称: month
显式索引: 1
显式索引: a 1
b 2
c 3
Name: month, dtype: int64
隐式索引: 2
隐式索引: b 2
c 3
Name: month, dtype: int64
标签访问: 1
位置访问: 2(5)数据访问
|
函数 |
描述 |
|
s.iloc[0] |
通过整数位置访问(从0开始) |
|
s.iloc[1:3] |
位置切片(左闭右开) |
|
s.loc['a'] |
通过索引标签访问 |
|
s.loc[['a','b']] |
通过标签列表访问 |
|
s[0] |
类似iloc(当索引非整数时可能混淆) |
|
s['a'] |
类似loc(优先标签索引) |
|
s[s > 3] |
通过布尔条件筛选 |
|
s[~(s > 3)] |
取反条件 |
|
s.at['a'] |
快速访问单个标签(类似loc但效率更高) |
|
s.iat[0] |
快速访问单个位置(类似iloc但效率更高) |
|
s.head(3) |
访问前N行(默认5) |
|
s.tail(2) |
访问后N行(默认5) |
|
s.unique() |
返回唯一值数组 |
|
s.value_counts() |
统计各值出现次数 |
arr = pd.Series([1,2,3,4,5,6], index=['a','b','c','d','e','f'], name='month')
# 直接取值
# print('直接取值: ', arr[0])
print('直接取值: ', arr['a'])
# 布尔索引
print('布尔索引: ', arr[arr > 3])
# 取反
print('布尔索引取反: ', arr[~(arr > 3)])
# 取前N行
print('取前N行: ', arr.head())
print('取前N行: ', arr.head(2))
# 取后N行
print('取后N行: ', arr.tail())
print('取后N行: ', arr.tail(2))
# 输出----------------------------------------
直接取值: 1
布尔索引: d 4
e 5
f 6
Name: month, dtype: int64
布尔索引取反: a 1
b 2
c 3
Name: month, dtype: int64
取前N行: a 1
b 2
c 3
d 4
e 5
Name: month, dtype: int64
取前N行: a 1
b 2
Name: month, dtype: int64
取后N行: b 2
c 3
d 4
e 5
f 6
Name: month, dtype: int64
取后N行: e 5
f 6
Name: month, dtype: int64(6)常用方法
|
分类 |
方法 |
说明 |
|
数据预览 |
head() |
查看前 n 行数据,默认 5 行 |
|
tail() |
查看后 n 行数据,默认 5 行 |
|
|
条件判断 |
isin() |
判断元素是否包含在参数集合中 |
|
缺失值处理 |
isna() |
判断是否为缺失值(如 NaN 或 None) |
|
聚合统计 |
sum() |
求和,自动忽略缺失值 |
|
mean() |
平均值 |
|
|
min() |
最小值 |
|
|
max() |
最大值 |
|
|
var() |
方差 |
|
|
std() |
标准差 |
|
|
median() |
中位数 |
|
|
mode() |
众数(可返回多个) |
|
|
quantile(q) |
分位数,q 取 0~1 之间 |
|
|
describe() |
常见统计信息(count、mean、std、min、25%、50%、75%、max) |
|
|
频率统计 |
value_counts() |
每个唯一值的出现次数 |
|
count() |
非缺失值数量 |
|
|
nunique() |
唯一值个数(去重) |
|
|
唯一处理 |
unique() |
获取去重后的值数组 |
|
drop_duplicates() |
去除重复项 |
|
|
抽样分析 |
sample() |
随机抽样 |
|
排序操作 |
sort_index() |
按索引排序 |
|
sort_values() |
按值排序 |
|
|
替换值 |
replace() |
替换值 |
|
转换结构 |
to_frame() |
将 Series 转为 DataFrame |
|
比较判断 |
equals() |
判断两个 Series 是否完全相等 |
|
信息提取 |
keys() |
返回 Series 的索引对象 |
|
统计关系 |
corr() |
计算相关系数(默认皮尔逊) |
|
cov() |
协方差 |
|
|
可视化 |
hist() |
绘制直方图(需安装 matplotlib) |
|
遍历操作 |
items() |
返回索引和值的迭代器 |
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# 查看前n行数据,默认5行
print('查看前n行数据,默认5行: ', arrs.head(3))
# 查看后n行数据,默认5行
print('查看后n行数据,默认5行: ', arrs.tail(3))
# 判断元素是否包含在参数集合中
print('是否包含在参数集合中: ', arrs.isin([11]))
# 判断是否为缺失值
print('是否为缺失值: ', arrs.isna())
# 求和,自动忽略缺失值
print('求和: ', arrs.sum())
# 平均值
print('平均值: ', arrs.mean())
# 最小值
print('最小值: ', arrs.min())
# 最大值
print('最大值: ', arrs.max())
# 方差
print('方差: ', arrs.var())
# 标准差
print('标准差: ', arrs.std())
# 中位数
print('中位数: ', arrs.median())
print('============')
# 众数(可返回多个)
print('众数: ', arrs.mode())
print('============')
# 分位数,q 取 0~1 之间
print('分位数: ', arrs.quantile())
print('============')
# 常见统计信息
print('常见统计信息: ', arrs.describe())
print('============')
# 每个唯一值的出现次数
print('每个唯一值的出现次数: ', arrs.value_counts())
# 非缺失值数量
print('非缺失值数量: ', arrs.count())
# 唯一值个数(去重)
print('唯一值个数: ', arrs.nunique())
# 获取去重后的值数组
print('去重后的值数组: ', arrs.unique())
# 去除重复项
print('去除重复项: ', arrs.drop_duplicates())
# 随机抽样
print('随机抽样: ', arrs.sample())
# 按索引排序
print('按索引排序: ', arrs.sort_index())
# 按值排序
print('按值排序: ', arrs.sort_values())
# 替换值
print('替换值: ', arrs.replace({11: 100}))
# 返回 Series 的索引对象
print('索引对象: ', arrs.keys())
# 输出-----------------------------------------
查看前n行数据,默认5行: a 11.0
b 22.0
c NaN
dtype: float64
查看后n行数据,默认5行: d NaN
e 44.0
f 22.0
dtype: float64
是否包含在参数集合中: a True
b False
c False
d False
e False
f False
dtype: bool
是否为缺失值: a False
b False
c True
d True
e False
f False
dtype: bool
求和: 99.0
平均值: 24.75
最小值: 11.0
最大值: 44.0
方差: 191.58333333333334
标准差: 13.841363131329707
中位数: 22.0
============
众数: 0 22.0
dtype: float64
============
分位数: 22.0
============
常见统计信息: count 4.000000
mean 24.750000
std 13.841363
min 11.000000
25% 19.250000
50% 22.000000
75% 27.500000
max 44.000000
dtype: float64
============
每个唯一值的出现次数: 22.0 2
11.0 1
44.0 1
Name: count, dtype: int64
非缺失值数量: 4
唯一值个数: 3
去重后的值数组: [11. 22. nan 44.]
去除重复项: a 11.0
b 22.0
c NaN
e 44.0
dtype: float64
随机抽样: f 22.0
dtype: float64
按索引排序: a 11.0
b 22.0
c NaN
d NaN
e 44.0
f 22.0
dtype: float64
按值排序: a 11.0
b 22.0
f 22.0
e 44.0
c NaN
d NaN
dtype: float64
替换值: a 100.0
b 22.0
c NaN
d NaN
e 44.0
f 22.0
dtype: float64
索引对象: Index(['a', 'b', 'c', 'd', 'e', 'f'], dtype='object')(7)案例
1)学生成绩统计
创建一个包含10名学生数学成绩的Series,成绩范围在50-100之间。计算平均分、最高分、最低分,并找出高于平均分的学生人数。
np.random.seed(1)
scores = pd.Series(np.random.randint(50, 101, 10), index=['学生'+str(i) for i in range(1, 11)], name='score')
print(scores)
# 平均分、最高分、最低分,并找出高于平均分的学生人数
print('平均分: ', scores.mean())
print('最高分: ', scores.max())
print('最低分: ', scores.min())
print('高于平均分的学生人数: ', scores[scores > scores.mean()])
# 输出---------------------------------------------------
学生1 87
学生2 93
学生3 62
学生4 58
学生5 59
学生6 61
学生7 55
学生8 65
学生9 50
学生10 66
Name: score, dtype: int32
平均分: 65.6
最高分: 93
最低分: 50
高于平均分的学生人数: 学生1 87
学生2 93
学生10 66
Name: score, dtype: int322)温度数据分析
给定某城市一周每天的最高温度Series,完成以下任务:
- 找出温度超过30度的天数
- 计算平均温度
- 将温度从高到低排序
- 找出温度变化最大的两天
temperatures = pd.Series([28, 31, 29, 32, 30, 27, 33], index=['周一', '周二', '周三', '周四', '周五', '周六', '周日'])
# 找出温度超过30度的天数
print('温度超过30度的天数: ', temperatures[temperatures > 30])
# 计算平均温度
print('平均温度: ', temperatures.mean())
# 将温度从高到低排序
print('温度从高到低排序: ', temperatures.sort_values(ascending=False))
# 找出温度变化最大的两天
print('温度变化最大的两天: ', temperatures.nlargest(2))
# 输出----------------------------------------------------
温度超过30度的天数: 周二 31
周四 32
周日 33
dtype: int64
平均温度: 30.0
温度从高到低排序: 周日 33
周四 32
周二 31
周五 30
周三 29
周一 28
周六 27
dtype: int64
温度变化最大的两天: 周日 33
周四 32
dtype: int64
3)股票价格分析
给定某股票连续10个交易日的收盘价Series:
- 计算每日收益率(当日收盘价/前日收盘价 - 1)
- 找出收益率最高和最低的日期
- 计算波动率(收益率的标准差)
prices = pd.Series([102.3, 103.5, 105.1, 104.8, 106.2, 107.0, 106.5, 108.1, 109.3, 110.2], index=pd.date_range('2025-01-01', periods=10))
# 计算每日收益率(当日收盘价/前日收盘价- 1)
print('计算每日收益率: ', prices.pct_change())
# 找出收益率最高和最低的日期
print('收益率最高的日期: ', prices.idxmax())
print('收益率最低的日期: ', prices.idxmin())
# 计算波动率(收益率的标准差)
print('波动率: ', prices.std())
# 输出-----------------------------------
计算每日收益率: 2025-01-01 NaN
2025-01-02 0.011730
2025-01-03 0.015459
2025-01-04 -0.002854
2025-01-05 0.013359
2025-01-06 0.007533
2025-01-07 -0.004673
2025-01-08 0.015023
2025-01-09 0.011101
2025-01-10 0.008234
Freq: D, dtype: float64
收益率最高的日期: 2025-01-10 00:00:00
收益率最低的日期: 2025-01-01 00:00:00
波动率: 2.4837248013596224、DataFrame数据结构
(1)介绍
DataFrame 是 Pandas 中的核心数据结构之一,多行多列表格数据,类似于 Excel 表格 或 SQL 查询结果。 它是一个 二维表格结构,具有行索引(index)和列标签(columns)。
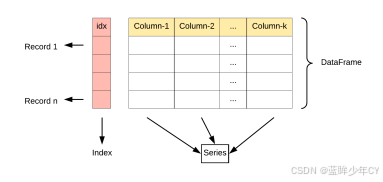
DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。它可以被看做由Series组成的字典(共同用一个索引)。提供了各种功能来进行数据访问、筛选、分割、合并、重塑、聚合以及转换等操作,广泛用于数据分析、清洗、转换、可视化等任务。
(2)创建
- 通过Series创建
- 通过字典创建
- 通过字典创建时指定列的顺序和行索引
# 通过Series创建
arr1 = pd.Series([1, 2, 3, 4])
arr2 = pd.Series([5, 6, 7, 8])
arr = pd.DataFrame({'第一列': arr1, '第二列:': arr2})
print(arr)
print('-------------------')
# 通过字典创建
arr = pd.DataFrame({
'name': ['lisi', 'wnagwu', 'zhangshan'],
'age': [10, 20, 30],
'scores': [60.5, 80, 90.5]
})
print(arr)
print('-------------------')
# 通过字典创建时指定列的顺序和行索引
arr = pd.DataFrame({
'name': ['lisi', 'wnagwu', 'zhangshan'],
'age': [10, 20, 30],
'scores': [60.5, 80, 90.5]
}, columns=['name','scores', 'age'], index=['101', '102', '103'])
print(arr)
# 输出------------------------------
第一列 第二列:
0 1 5
1 2 6
2 3 7
3 4 8
-------------------
name age scores
0 lisi 10 60.5
1 wnagwu 20 80.0
2 zhangshan 30 90.5
-------------------
name scores age
101 lisi 60.5 10
102 wnagwu 80.0 20
103 zhangshan 90.5 30(3)常用属性
|
属性 |
说明 |
|
index |
DataFrame的行索引 |
|
columns |
DataFrame的列标签 |
|
values |
DataFrame的值 |
|
ndim |
DataFrame的维度 |
|
shape |
DataFrame的形状 |
|
size |
DataFrame的元素个数 |
|
dtypes |
DataFrame的元素类型 |
|
T |
行列转置 |
|
loc[] |
显式索引,按行列标签索引或切片 |
|
iloc[] |
隐式索引,按行列位置索引或切片 |
|
at[] |
使用行列标签访问单个元素 |
|
iat[] |
使用行列位置访问单个元素 |
# 获取行索引
print('行索引', arr.index)
# 获取列标签
print('列标签', arr.columns)
# 获取值
print('获取值')
print(arr.values)
# 获取维度
print('获取维度:', arr.ndim)
# 获取元素类型
print('获取元素类型:', arr.dtypes)
# 转置
print('转置:', arr.T)
# 获取某行元素
print('获取某行元素')
print(arr.loc['101'])
print(arr.iloc[0])
print('获取某行元素')
print(arr.loc['101' : '102'])
print(arr.iloc[0 : 2])
print('获取某列元素')
print(arr.loc[: , 'name'])
print(arr.iloc[: , 0])
# 使用行列标签访问单个元素
print('获取单个元素')
print(arr.at['101', 'name'])
print(arr.iat[0, 0])
print(arr.loc['101', 'name'])
print(arr.iloc[0, 0])
# 输出-----------------------------
行索引 Index(['101', '102', '103'], dtype='object')
列标签 Index(['name', 'scores', 'age'], dtype='object')
获取值
[['lisi' 60.5 10]
['wnagwu' 80.0 20]
['zhangshan' 90.5 30]]
获取维度: 2
获取元素类型: name object
scores float64
age int64
dtype: object
转置: 101 102 103
name lisi wnagwu zhangshan
scores 60.5 80.0 90.5
age 10 20 30
获取某行元素
name lisi
scores 60.5
age 10
Name: 101, dtype: object
name lisi
scores 60.5
age 10
Name: 101, dtype: object
获取某行元素
name scores age
101 lisi 60.5 10
102 wnagwu 80.0 20
name scores age
101 lisi 60.5 10
102 wnagwu 80.0 20
获取某列元素
101 lisi
102 wnagwu
103 zhangshan
Name: name, dtype: object
101 lisi
102 wnagwu
103 zhangshan
Name: name, dtype: object
获取单个元素
lisi
lisi
lisi
lisi
(4)数据访问
|
方法分类 |
语法示例 |
描述 |
|
列选择 |
df['col'] |
选择单列(返回Series) |
| df.'col' | 选择单列(返回Series) | |
|
df[['col1', 'col2']] |
选择多列(返回DataFrame) |
|
|
行选择 |
df.loc[row_label] |
通过行标签选择单行(返回Series) |
|
df.loc[start:end] |
通过标签切片选择多行(闭区间) |
|
|
df.iloc[row_index] |
通过行位置选择单行(从0开始) |
|
|
df.iloc[start:end] |
通过位置切片选择多行(左闭右开) |
|
|
行列组合选择 |
df.loc[row_labels, col_labels] |
通过标签选择行和列(如df.loc['a':'b', ['col1','col2']]) |
|
df.iloc[row_idx, col_idx] |
通过位置选择行和列(如df.iloc[0:2, [1,3]]) |
|
|
条件筛选 |
df[df['col'] > 3] |
通过布尔条件筛选行 |
|
df.query("col1 > 3 & col2 < 10") |
使用表达式筛选(需字符串表达式) |
|
|
快速访问 |
df.at[row_label, 'col'] |
快速访问单个值(标签索引,高效) |
|
df.iat[row_idx, col_idx] |
快速访问单个值(位置索引,高效) |
|
|
头部/尾部 |
df.head(n) |
返回前n行(默认5) |
|
df.tail(n) |
返回后n行(默认5) |
|
|
样本抽样 |
df.sample(n=3) |
随机抽取n行 |
|
索引重置 |
df.reset_index() |
重置索引(原索引变为列) |
|
设置索引 |
df.set_index('col') |
指定某列作为新索引 |
# 获取单列数据
print('获取单列数据')
print(arr['name'])
print('===================')
print(arr.name)
print('===================')
print(arr[['name']])
print('===================')
print(arr[['name', 'scores']])
# 返回前n行
print('返回前2行: ')
print(arr.head(2))
# 条件筛选
print('条件筛选')
print(arr[arr['scores'] > 70])
print(arr[(arr['scores'] > 70) & (arr['scores'] <= 80)])
# 输出============================
获取单列数据
101 lisi
102 wnagwu
103 zhangshan
Name: name, dtype: object
===================
101 lisi
102 wnagwu
103 zhangshan
Name: name, dtype: object
===================
name
101 lisi
102 wnagwu
103 zhangshan
===================
name scores
101 lisi 60.5
102 wnagwu 80.0
103 zhangshan 90.5
返回前2行:
name scores age
101 lisi 60.5 10
102 wnagwu 80.0 20
条件筛选
name scores age
102 wnagwu 80.0 20
103 zhangshan 90.5 30
name scores age
102 wnagwu 80.0 20(5)常用方法
|
方法 |
说明 |
|
head() |
查看前n行数据,默认5行 |
|
tail() |
查看后n行数据,默认5行 |
|
isin() |
元素是否包含在参数集合中 |
|
isna() |
元素是否为缺失值 |
|
sum() |
求和 |
|
mean() |
平均值 |
|
min() |
最小值 |
|
max() |
最大值 |
|
var() |
方差 |
|
std() |
标准差 |
|
median() |
中位数 |
|
mode() |
众数 |
|
quantile() |
指定位置的分位数,如quantile(0.5) |
|
describe() |
常见统计信息 |
|
info() |
基本信息 |
|
value_counts() |
每个元素的个数 |
|
count() |
非空元素的个数 |
|
drop_duplicates() |
去重 |
|
sample() |
随机采样 |
|
replace() |
用指定值代替原有值 |
|
equals() |
判断两个DataFrame是否相同 |
|
cummax() |
累计最大值 |
|
cummin() |
累计最小值 |
|
cumsum() |
累计和 |
|
cumprod() |
累计积 |
|
diff() |
一阶差分,对序列中的元素进行差分运算,也就是用当前元素减去前一个元素得到差值,默认情况下,它会计算一阶差分,即相邻元素之间的差值。参数: periods:整数,默认为 1。表示要向前或向后移动的周期数,用于计算差值。正数表示向前移动,负数表示向后移动。 axis:指定计算的轴方向。0 或 'index' 表示按列计算,1 或 'columns' 表示按行计算,默认值为 0。 |
|
sort_index() |
按行索引排序 |
|
sort_values() |
按某列的值排序,可传入列表来按多列排序,并通过ascending参数设置升序或降序 |
|
nlargest() |
返回某列最大的n条数据 |
|
nsmallest() |
返回某列最小的n条数据 |
print(df)
# 查看前3行数据
print('查看前3行数据')
print(df.head(3))
# 查看后3行数据
print('查看后3行数据')
print(df.tail(3))
# 元素是否包含在参数集合中
print('元素是否包含在参数集合中')
print(df.isin(['李四', 10]))
# 元素是否为缺失值
print('元素是否为缺失值')
print(df.isna())
# 求和
print('求和: ', df['age'].sum())
# 平均值
print('平均值: ', df.age.mean())
# 最小值
print('最小值: ', df.age.min())
# 最大值
print('最大值: ', df['age'].max())
# 方差
print('方差: ', df['age'].var())
# 标准差
print('标准差: ', df['age'].std())
# 中位数
print('中位数: ', df['age'].median())
# 众数
print('众数: ', df['age'].mode())
# 分位数
print('分位数: ', df['age'].quantile(0.5))
# 常见统计信息
print('常见统计信息: ', df['age'].describe())
# 基本信息
print('基本信息: ')
print(df.info())
# 每个元素的个数
print('每个元素的个数: ')
print(df.value_counts())
# 非空元素的个数
print('非空元素的个数: ')
print(df.count())
# 判断是否为重复行
print('判断是否为重复行: ', df.duplicated())
# 判断某列是否为重复行
print('判断某列是否为重复行')
print(df.duplicated(subset=['age']))
# 随机采样
print('随机采样: ')
print(df.sample())
# 用指定值代替原有值
print('用指定值代替原有值')
print(df.replace(10, 101))
df2 = pd.DataFrame({'A': [2, 5, 3, 7, 4],'B': [1, 6, 2, 8, 3]})
# 累计最大值
print('列累计最大值:', df2.cummax(axis= 'index'))
print('行累计最大值: ', df2.cummax(axis='columns'))
# 累计最小值
print('累计最小值: ', df2.cummin())
# 累计和
print('累计和: ', df2.cumsum())
# 累计积
print('累计积: ', df2.cumprod())
# 按行索引排序
print('按行索引排序: ')
print(df.sort_index())
# 按某列的值排序
print('按某列的值排序: ')
print(df.sort_values(by='age', ascending=False))
# 返回某列最大的n条数据
print('返回某列最大的n条数据')
print(df.nlargest(n=2, columns='age'))
# 返回某列最小的n条数据
print('返回某列最小的n条数据')
print(df.nsmallest(n=2, columns='age'))
# 输出=============================================
id name age
aa 101 张三 10.0
bb 102 李四 20.0
cc 103 王五 30.0
dd 104 赵六 40.0
ee 105 冯七 NaN
ff 106 周八 60.0
aa 101 张三 10.0
查看前3行数据
id name age
aa 101 张三 10.0
bb 102 李四 20.0
cc 103 王五 30.0
查看后3行数据
id name age
ee 105 冯七 NaN
ff 106 周八 60.0
aa 101 张三 10.0
元素是否包含在参数集合中
id name age
aa False False True
bb False True False
cc False False False
dd False False False
ee False False False
ff False False False
aa False False True
元素是否为缺失值
id name age
aa False False False
bb False False False
cc False False False
dd False False False
ee False False True
ff False False False
aa False False False
求和: 170.0
平均值: 28.333333333333332
最小值: 10.0
最大值: 60.0
方差: 376.66666666666663
标准差: 19.407902170679517
中位数: 25.0
众数: 0 10.0
Name: age, dtype: float64
分位数: 25.0
常见统计信息: count 6.000000
mean 28.333333
std 19.407902
min 10.000000
25% 12.500000
50% 25.000000
75% 37.500000
max 60.000000
Name: age, dtype: float64
基本信息:
<class 'pandas.core.frame.DataFrame'>
Index: 7 entries, aa to aa
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 7 non-null int64
1 name 7 non-null object
2 age 6 non-null float64
dtypes: float64(1), int64(1), object(1)
memory usage: 524.0+ bytes
None
每个元素的个数:
id name age
101 张三 10.0 2
102 李四 20.0 1
103 王五 30.0 1
104 赵六 40.0 1
106 周八 60.0 1
Name: count, dtype: int64
非空元素的个数:
id 7
name 7
age 6
dtype: int64
判断是否为重复行: aa False
bb False
cc False
dd False
ee False
ff False
aa True
dtype: bool
判断某列是否为重复行
aa False
bb False
cc False
dd False
ee False
ff False
aa True
dtype: bool
随机采样:
id name age
ff 106 周八 60.0
用指定值代替原有值
id name age
aa 101 张三 101.0
bb 102 李四 20.0
cc 103 王五 30.0
dd 104 赵六 40.0
ee 105 冯七 NaN
ff 106 周八 60.0
aa 101 张三 101.0
列累计最大值: A B
0 2 1
1 5 6
2 5 6
3 7 8
4 7 8
行累计最大值: A B
0 2 2
1 5 6
2 3 3
3 7 8
4 4 4
累计最小值: A B
0 2 1
1 2 1
2 2 1
3 2 1
4 2 1
累计和: A B
0 2 1
1 7 7
2 10 9
3 17 17
4 21 20
累计积: A B
0 2 1
1 10 6
2 30 12
3 210 96
4 840 288
按行索引排序:
id name age
aa 101 张三 10.0
aa 101 张三 10.0
bb 102 李四 20.0
cc 103 王五 30.0
dd 104 赵六 40.0
ee 105 冯七 NaN
ff 106 周八 60.0
按某列的值排序:
id name age
ff 106 周八 60.0
dd 104 赵六 40.0
cc 103 王五 30.0
bb 102 李四 20.0
aa 101 张三 10.0
aa 101 张三 10.0
ee 105 冯七 NaN
返回某列最大的n条数据
id name age
ff 106 周八 60.0
dd 104 赵六 40.0
返回某列最小的n条数据
id name age
aa 101 张三 10.0
aa 101 张三 10.0在Pandas的 DataFrame 方法里,axis 是一个非常重要的参数,它用于指定操作的方向。
axis 参数可以取两个主要的值,即 0 或 'index',以及 1 或 'columns' ,其含义如下:
- axis=0 或 axis='index':表示操作沿着行的方向进行,也就是对每一列的数据进行处理。例如,当计算每列的均值时,就是对每列中的所有行数据进行计算。
- axis=1 或 axis='columns':表示操作沿着列的方向进行,也就是对每行的数据进行处理。例如,当计算每行的总和时,就是对每行中的所有列数据进行计算。
(6)案例
1)学生成绩分析
某班级的学生成绩数据如下,请完成以下任务:
- 计算每位学生的总分和平均分。
- 找出数学成绩高于90分或英语成绩高于85分的学生。
- 按总分从高到低排序,并输出前3名学生。
data = {
'姓名': ['张三', '李四', '王五', '赵六', '钱七'],
'数学': [85, 92, 78, 88, 95],
'英语': [90, 88, 85, 92, 80],
'物理': [75, 80, 88, 85, 90]
}
df = pd.DataFrame(data)
df
# 计算每位学生的总分和平均分。
print('总分')
countF = df[['数学', '英语', '物理']].sum(axis=1)
df['总分'] = countF
print(countF)
print('平均分')
print(df[['数学', '英语', '物理']].mean(axis=1))
# 找出数学成绩高于90分或英语成绩高于85分的学生。
print('数学成绩高于90分或英语成绩高于85分的学生')
print(df[(df['数学'] > 90) | (df['英语'] > 85 )])
#按总分从高到低排序,并输出前3名学生。
print('按总分从高到低排序,并输出前3名学生')
print(df.sort_values('总分', ascending=False).head(3))
# 输出=============================
总分
0 250
1 260
2 251
3 265
4 265
dtype: int64
平均分
0 83.333333
1 86.666667
2 83.666667
3 88.333333
4 88.333333
dtype: float64
数学成绩高于90分或英语成绩高于85分的学生
姓名 数学 英语 物理 总分
0 张三 85 90 75 250
1 李四 92 88 80 260
3 赵六 88 92 85 265
4 钱七 95 80 90 265
按总分从高到低排序,并输出前3名学生
姓名 数学 英语 物理 总分
3 赵六 88 92 85 265
4 钱七 95 80 90 265
1 李四 92 88 80 2602)销售数据分析
某公司销售数据如下,请完成以下任务:
- 计算每种产品的总销售额(销售额 = 单价 × 销量)。
- 找出销售额最高的产品。
- 按销售额从高到低排序,并输出所有产品信息。
data = {
'产品名称': ['A', 'B', 'C', 'D'],
'单价': [100, 150, 200, 120],
'销量': [50, 30, 20, 40]
}
df = pd.DataFrame(data)
# 计算每种产品的总销售额(销售额= 单价× 销量)。
sx = df['单价'] * df['销量']
df['销售额'] = sx
print('销售额')
print(sx)
# 找出销售额最高的产品。
print('销售额最高的产品')
print(df.sort_values('销售额', ascending=False).head(1))
print('或者')
print(df[ df['销售额'] == df['销售额'].max() ])
# 按销售额从高到低排序,并输出所有产品信息。
print('从高到低排序')
print(df.sort_values('销售额', ascending=False))
# 输出============================================
销售额
0 5000
1 4500
2 4000
3 4800
dtype: int64
销售额最高的产品
产品名称 单价 销量 销售额
0 A 100 50 5000
或者
产品名称 单价 销量 销售额
0 A 100 50 5000
从高到低排序
产品名称 单价 销量 销售额
0 A 100 50 5000
3 D 120 40 4800
1 B 150 30 4500
2 C 200 20 40003)工考勤统计
某部门员工考勤数据如下,请完成以下任务:
- 计算每位员工的出勤率(出勤率 = 出勤天数 / 工作日总数)。
- 标记出勤率低于80%的员工。
- 按出勤率从高到低排序。
data = {
'姓名': ['张三', '李四', '王五', '赵六'],
'出勤天数': [20, 15, 18, 22],
'工作日总数': [25, 20, 25, 25]
}
df = pd.DataFrame(data)
# 计算每位员工的出勤率(出勤率= 出勤天数/ 工作日总数)。
cql = df['出勤天数'] / df['工作日总数']
df['出勤率'] = cql
print('出勤率')
print(cql)
# 标记出勤率低于80%的员工。
print('出勤率低于80%的员工')
print(df[ df['出勤率'] < 0.8])
# 按出勤率从高到低排序。
print('出勤率从高到低排序')
print(df.sort_values('出勤率', ascending=False))
# 输出==============================================
出勤率
0 0.80
1 0.75
2 0.72
3 0.88
dtype: float64
出勤率低于80%的员工
姓名 出勤天数 工作日总数 出勤率
1 李四 15 20 0.75
2 王五 18 25 0.72
出勤率从高到低排序
姓名 出勤天数 工作日总数 出勤率
3 赵六 22 25 0.88
0 张三 20 25 0.80
1 李四 15 20 0.75
2 王五 18 25 0.724)电影评分分析
某电影评分数据如下,请完成以下任务:
- 计算每部电影的平均评分。
- 找出评分高于8.5的电影。
- 按平均评分从高到低排序。
data = {
'电影名称': ['电影A', '电影B', '电影C', '电影D'],
'评分1': [9.0, 8.5, 8.0, 7.5],
'评分2': [8.5, 9.0, 8.5, 8.0],
'评分3': [9.5, 8.0, 7.5, 7.0]
}
df = pd.DataFrame(data)
# 计算每部电影的平均评分。
avg = df[['评分1', '评分2', '评分3']].mean(axis=1).round(2)
df['平均评分'] = avg
print('平均评分')
print(avg)
# 找出评分高于8.5的电影。
print('评分高于8.5的电影')
print(df[ df['平均评分'] > 8.5 ])
# 按平均评分从高到低排序。
print('平均评分从高到低排序')
print(df.sort_values('平均评分', ascending=False))
# 输出==============================
平均评分
0 9.0
1 8.5
2 8.0
3 7.5
dtype: float64
评分高于8.5的电影
电影名称 评分1 评分2 评分3 平均评分
0 电影A 9.0 8.5 9.5 9.0
平均评分从高到低排序
电影名称 评分1 评分2 评分3 平均评分
0 电影A 9.0 8.5 9.5 9.0
1 电影B 8.5 9.0 8.0 8.5
2 电影C 8.0 8.5 7.5 8.0
3 电影D 7.5 8.0 7.0 7.55)股票价格分析
某股票价格数据如下,请完成以下任务:
- 计算每日股价的涨跌幅(涨跌幅 = (当日收盘价 - 前一日收盘价) / 前一日收盘价)。
- 找出涨幅超过5%的日期。
- 按日期排序,并输出涨跌幅最高的日期。
data = {
'日期': ['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04'],
'收盘价': [100, 105, 110, 102]
}
df = pd.DataFrame(data)
# 计算每日股价的涨跌幅(涨跌幅 = (当日收盘价 - 前一日收盘价) / 前一日收盘价)。
zf = df['收盘价'].pct_change().round(2)
df['涨跌幅'] = zf
print(zf)
# 找出涨幅超过5%的日期。
print('涨幅超过5%的日期')
print(df[ df['涨跌幅'] > 0.05]['日期'])
# 按日期排序,并输出涨跌幅最高的日期。
print('按日期排序')
print(df.sort_values('日期'))
print('涨跌幅最高的日期')
print(df.loc[ df['涨跌幅'].idxmax(), '日期'])
# 输出======================================================
0 NaN
1 0.05
2 0.05
3 -0.07
Name: 收盘价, dtype: float64
涨幅超过5%的日期
Series([], Name: 日期, dtype: object)
按日期排序
日期 收盘价 涨跌幅
0 2023-01-01 100 NaN
1 2023-01-02 105 0.05
2 2023-01-03 110 0.05
3 2023-01-04 102 -0.07
涨跌幅最高的日期
2023-01-026)电商用户行为分析(基础版)
某电商平台的用户行为数据如下,请完成以下任务:
- 计算每位用户的**总消费金额**(消费金额 = 商品单价 × 购买数量)
- 找出**消费金额最高的用户**,并输出其所有信息
- 计算所有用户的**平均消费金额**(保留2位小数)
- 统计**电子产品**的总购买数量
data = {
'用户ID': [101, 102, 103, 104, 105],
'用户名': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'商品类别': ['电子产品', '服饰', '电子产品', '家居', '服饰'],
'商品单价': [1200, 300, 800, 150, 200],
'购买数量': [1, 3, 2, 5, 4]
}
df = pd.DataFrame(data)
# 输出===================================
# 计算每位用户的**总消费金额**(消费金额 = 商品单价 × 购买数量)
zxf = df['商品单价'] * df['购买数量']
df['消费金额'] = zxf
print('总消费金额')
print(zxf)
# 找出**消费金额最高的用户**,并输出其所有信息
print('消费金额最高的用户')
print(df[df['消费金额'] == df['消费金额'].max()])
# 计算所有用户的**平均消费金额**(保留2位小数)
print('平均消费金额')
print(df['消费金额'].mean().round(2))
# 统计**电子产品**的总购买数量
print('总购买数量')
print(df[df['商品类别'] == '电子产品']['购买数量'].sum())5、数据的导入与导出
(1)数据导入
|
方法 |
说明 |
|
read_csv() |
加载csv格式的数据。可通过sep参数指定分隔符,可通过index_col参数指定行索引 |
|
read_pickle() |
加载pickle格式的数据。 |
|
read_excel() |
加载Excel格式的数据。 |
|
read_clipboard() |
加载剪切板中的数据。 |
|
read_hdf() |
加载HDF格式的数据。 |
|
read_html() |
加载HTML格式的数据。 |
|
read_json() |
加载JSON格式的数据。 |
|
read_feather() |
加载feather格式的数据。 |
|
read_sql() |
加载数据库中的数据。 |
- 加载csv文件
import pandas as pd;
# 导入csv文件
df = pd.read_csv('data/employees.csv')
print(df.tail(5))
print('====================')
print(df.tail(5)['salary'].mean())
# 输出=================
employee_id first_name last_name email phone_number job_id \
102 202 Pat Fay PFAY 603.123.6666 MK_REP
103 203 Susan Mavris SMAVRIS 515.123.7777 HR_REP
104 204 Hermann Baer HBAER 515.123.8888 PR_REP
105 205 Shelley Higgins SHIGGINS 515.123.8080 AC_MGR
106 206 William Gietz WGIETZ 515.123.8181 AC_ACCOUNT
salary commission_pct manager_id department_id
102 6000.0 NaN 201.0 20.0
103 6500.0 NaN 101.0 40.0
104 10000.0 NaN 101.0 70.0
105 12000.0 NaN 101.0 110.0
106 8300.0 NaN 205.0 110.0
====================
8560.0
- 加载简单json文件
# 读取简单json文件
df = pd.read_json('data/data1.json')
print(df)
print('=================')
print(df['age'].sum())
# 输出==============================
id name age
0 1 张三 25
1 2 李四 30
2 3 王五 28
=================
83
- 加载复杂的json文件
# 读取复杂的json文件
df = pd.read_json('data/test.json')
df
import json
with open('data/test.json') as f:
data = json.load(f)
print(data['users'])
print('====================')
df = pd.DataFrame(data['users'])
df
(2)数据导出
|
方法 |
说明 |
|
to_csv() |
将数据保存为csv格式文件,数据之间以逗号分隔,可通过sep参数设置使用其他分隔符,可通过index参数设置是否保存行标签,可通过header参数设置是否保存列标签。 |
|
to_pickle() |
如要保存的对象是计算的中间结果,或者保存的对象以后会在Python中复用,可把对象保存为.pickle文件。如果保存成pickle文件,只能在python中使用。文件的扩展名可以是.p、.pkl、.pickle。 |
|
to_excel() |
保存为Excel文件,需安装openpyxl包。 |
|
to_clipboard() |
保存到剪切板。 |
|
to_dict() |
保存为字典。 |
|
to_hdf() |
保存为HDF格式,需安装tables包。 |
|
to_html() |
保存为HTML格式,需安装lxml、html5lib、beautifulsoup4包。 |
|
to_json() |
保存为JSON格式。 |
|
to_feather() |
feather是一种文件格式,用于存储二进制对象。feather对象也可以加载到R语言中使用。feather格式的主要优点是在Python和R语言之间的读写速度要比csv文件快。feather数据格式通常只用中间数据格式,用于Python和R之间传递数据,一般不用做保存最终数据。需安装pyarrow包。 |
|
to_sql() |
保存到数据库。 |
# 导出csv文件
import json
import pandas as pd
with open('data/test.json') as f:
data = json.load(f)
df = pd.DataFrame(data['users'])
df.to_csv('data/test_new.csv')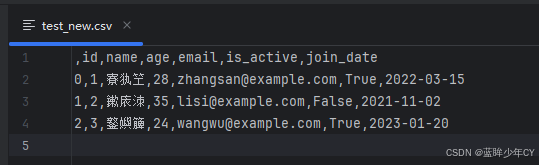
6、数据清洗与预处理
(1)缺失值处理
|
语法示例 |
描述 |
|
df.isna() 或 df.isnull() |
检测缺失值,返回布尔矩阵,标记缺失值(NaN或None) |
|
df.isna().sum() |
统计缺失值,每列缺失值数量统计 |
|
df.dropna() |
删除包含缺失值的行(默认) |
|
df.dropna(axis=1) |
删除包含缺失值的列 |
|
df.dropna(how='all') |
如果某一行所有的值都是缺失值,则删除这一行 |
|
df.dropna(thresh='n') |
至少有n个值不是缺失值,则保留这一行 |
|
df.dropna(subset=['col1']) |
仅删除指定列的缺失值行 |
|
df.fillna(value) |
用固定值填充,如df.fillna(0) |
|
df.fillna(method='ffill') |
用前一个非缺失值填充(向前填充) |
|
df.fillna(method='bfill') |
用后一个非缺失值填充(向后填充) |
|
df.fillna(df.mean()) |
用列均值填充 |
- 检查缺失值
在加载文件数据是可以通过keep_default_na参数设置是否将空白值设置为缺失值
import pandas as pd
import numpy as np
s = pd.Series([1, 3, 5, np.nan, None, pd.NA])
df = pd.DataFrame([[1,pd.NA,2],[2,3,5],[None,4,6]], columns=['A','B','C'])
print('检查缺失值========')
print(pd.isna(s))
print('-'*10)
print(s.isnull())
print('='*10)
print(pd.isna(df))
print('-'*10)
print(df.isnull())
# 输出===============================
检查缺失值========
0 False
1 False
2 False
3 True
4 True
5 True
dtype: bool
----------
0 False
1 False
2 False
3 True
4 True
5 True
dtype: bool
==========
A B C
0 False True False
1 False False False
2 True False False
----------
A B C
0 False True False
1 False False False
2 True False False- 统计缺失值
print(s)
print('统计缺失值========')
print(pd.isna(s).sum())
print('='*10)
print(df)
print('-'*10 + '列统计')
print(pd.isna(df).sum())
print('-'*10 + '行统计')
print(pd.isna(df).sum(axis=1))
# 输出===============================
0 1
1 3
2 5
3 NaN
4 None
5 <NA>
dtype: object
统计缺失值========
3
==========
A B C
0 1.0 <NA> 2
1 2.0 3 5
2 NaN 4 6
----------列统计
A 1
B 1
C 0
dtype: int64
----------行统计
0 1
1 0
2 1
dtype: int64- 剔除缺失值
# 剔除缺失值
df = pd.DataFrame([[1,pd.NA,2],[2,3,5],[None,4,6]], columns=['A','B','C'])
print(df)
# 如果某一行有缺失值,择剔除一整行
print('==如果某一行有缺失值,则剔除一整行==')
print(df.dropna())
# 如果某一行所有的值都是缺失值,则剔除一整行
print('==如果某一行所有的值都是缺失值,则剔除一整行==')
print(df.dropna(how='all'))
# 如果至少有n个值不是缺失值,则保留这一行
print('==如果至少有n个值不是缺失值,则保留这一行==')
print(df.dropna(thresh=3))
print('@'*20)
# 如果某一列有缺失值,择剔除一整列
print('==如果某一列有缺失值,择剔除一整列==')
print(df.dropna(axis=1))
# 如果某一列所有的值都是缺失值,则剔除一整列
print('==如果某一列所有的值都是缺失值,则剔除一整列==')
print(df.dropna(how='all', axis=1))
# 如果至少有n个值不是缺失值,则保留这一列
print('==如果至少有n个值不是缺失值,则保留这一列==')
print(df.dropna(thresh=3, axis=1))
#如果某列有缺失值,则删除这一行
print('==如果某列有缺失值,则删除这一行==')
print(df.dropna(subset=['A']))
# 输出==============================
A B C
0 1.0 <NA> 2
1 2.0 3 5
2 NaN 4 6
==如果某一行有缺失值,则剔除一整行==
A B C
1 2.0 3 5
==如果某一行所有的值都是缺失值,则剔除一整行==
A B C
0 1.0 <NA> 2
1 2.0 3 5
2 NaN 4 6
==如果至少有n个值不是缺失值,则保留这一行==
A B C
1 2.0 3 5
@@@@@@@@@@@@@@@@@@@@
==如果某一列有缺失值,择剔除一整列==
C
0 2
1 5
2 6
==如果某一列所有的值都是缺失值,则剔除一整列==
A B C
0 1.0 <NA> 2
1 2.0 3 5
2 NaN 4 6
==如果至少有n个值不是缺失值,则保留这一列==
C
0 2
1 5
2 6
==如果某列有缺失值,则删除这一行==
A B C
0 1.0 <NA> 2
1 2.0 3 5- 填充缺失值
# =====================数据填充=======================
# keep_default_na参数设置是否将空白值设置为缺失值
df = pd.read_csv('data/weather_withna.csv', keep_default_na=False)
print(df.tail(5))
# na_values参数将指定值设置为缺失值
df2 = pd.read_csv('data/weather_withna.csv', na_values=['hello'])
print('=='*10)
print(df2.tail(5))
df = pd.read_csv('data/weather_withna.csv')
# 查看缺失值数量
print('缺失值数量:')
print(df.isnull().sum())
# 使用固定值填充
print('使用固定值填充')
print(df.fillna(0).tail(5))
# 使用字典来填充
print('使用字典来填充')
print(df.fillna({'temp_max': -1, 'temp_min': -2}).tail(5))
# 使用统计值填充
print('使用统计值填充')
print(df.fillna(df[['precipitation']].mean()).tail())
# 使用前面的有效值填充
print('使用前面的有效值填充')
print(df.ffill().tail())
# 使用后面的有效值填充
print('使用后面的有效值填充')
print(df.bfill().tail())
# 输出=============================
date precipitation temp_max temp_min wind weather
1456 2015-12-27
1457 2015-12-28
1458 2015-12-29
1459 2015-12-30
1460 2015-12-31 20.6 12.2 5.0 3.8 rain
====================
date precipitation temp_max temp_min wind weather
1456 2015-12-27 NaN NaN NaN NaN NaN
1457 2015-12-28 NaN NaN NaN NaN NaN
1458 2015-12-29 NaN NaN NaN NaN NaN
1459 2015-12-30 NaN NaN NaN NaN NaN
1460 2015-12-31 20.6 12.2 5.0 3.8 rain
缺失值数量:
date 0
precipitation 303
temp_max 303
temp_min 303
wind 303
weather 303
dtype: int64
使用固定值填充
date precipitation temp_max temp_min wind weather
1456 2015-12-27 0.0 0.0 0.0 0.0 0
1457 2015-12-28 0.0 0.0 0.0 0.0 0
1458 2015-12-29 0.0 0.0 0.0 0.0 0
1459 2015-12-30 0.0 0.0 0.0 0.0 0
1460 2015-12-31 20.6 12.2 5.0 3.8 rain
使用字典来填充
date precipitation temp_max temp_min wind weather
1456 2015-12-27 NaN -1.0 -2.0 NaN NaN
1457 2015-12-28 NaN -1.0 -2.0 NaN NaN
1458 2015-12-29 NaN -1.0 -2.0 NaN NaN
1459 2015-12-30 NaN -1.0 -2.0 NaN NaN
1460 2015-12-31 20.6 12.2 5.0 3.8 rain
使用统计值填充
date precipitation temp_max temp_min wind weather
1456 2015-12-27 3.052332 NaN NaN NaN NaN
1457 2015-12-28 3.052332 NaN NaN NaN NaN
1458 2015-12-29 3.052332 NaN NaN NaN NaN
1459 2015-12-30 3.052332 NaN NaN NaN NaN
1460 2015-12-31 20.600000 12.2 5.0 3.8 rain
使用前面的有效值填充
date precipitation temp_max temp_min wind weather
1456 2015-12-27 0.0 11.1 4.4 4.8 sun
1457 2015-12-28 0.0 11.1 4.4 4.8 sun
1458 2015-12-29 0.0 11.1 4.4 4.8 sun
1459 2015-12-30 0.0 11.1 4.4 4.8 sun
1460 2015-12-31 20.6 12.2 5.0 3.8 rain
使用后面的有效值填充
date precipitation temp_max temp_min wind weather
1456 2015-12-27 20.6 12.2 5.0 3.8 rain
1457 2015-12-28 20.6 12.2 5.0 3.8 rain
1458 2015-12-29 20.6 12.2 5.0 3.8 rain
1459 2015-12-30 20.6 12.2 5.0 3.8 rain
1460 2015-12-31 20.6 12.2 5.0 3.8 rain(2)重复数据的处理
|
语法示例 |
描述 |
|
df.duplicated() |
检测重复行,返回布尔序列标记重复行(首次出现的行标记为False) |
|
df.drop_duplicates() |
删除重复行,保留首次出现的行(默认检查所有列) |
|
df.drop_duplicates(subset=['col1']) |
删除重复行,仅根据指定列去重 |
|
df.drop_duplicates(keep='last') |
删除重复行,保留最后一次出现的行 |
data = {
'Name': ['Alice', 'Bob', 'Alice', 'Charlie', 'Bob'],
'Age': [25, 30, 25, 35, 30],
'City': ['NY', 'LA', 'NY', 'SF', 'LA']
}
df = pd.DataFrame(data)
# 检测重复行(默认检查所有列)
print('检测重复行')
print(df.duplicated())
print('检测重复行,指定某一列')
print(df.duplicated(subset=['City']))
# 删除重复行,默认保留首次出现的行
print('删除重复行')
print(df.drop_duplicates())
# 仅根据'Name'列去重(保留首次出现)
print('仅根据名称列去重(保留首次出现)')
print(df.drop_duplicates(subset=['Name']))
# 保留最后一次出现的重复行
print('保留最后一次出现的重复行')
print(df.drop_duplicates(keep='last'))
# 输出====================================
检测重复行
0 False
1 False
2 True
3 False
4 True
dtype: bool
检测重复行,指定某一列
0 False
1 False
2 True
3 False
4 True
dtype: bool
删除重复行
Name Age City
0 Alice 25 NY
1 Bob 30 LA
3 Charlie 35 SF
仅根据名称列去重(保留首次出现)
Name Age City
0 Alice 25 NY
1 Bob 30 LA
3 Charlie 35 SF
保留最后一次出现的重复行
Name Age City
2 Alice 25 NY
3 Charlie 35 SF
4 Bob 30 LA注意事项
- 性能优化:对大数据集去重时,可通过 subset 指定关键列以减少计算量。
- 逻辑一致性:确保 keep='last' 或 keep=False(删除所有重复)符合业务需求。
- 多列去重:subset=['col1', 'col2'] 可联合多列判断重复。
(3)数据类型转换
|
操作 |
方法/函数 |
描述 |
|
查看数据类型 |
df.dtypes |
显示每列的数据类型(如int64、float64、object等)。 |
|
强制类型转换 |
df['col'].astype('type') |
将列转换为指定类型(如int、float、str、bool等)。 |
|
转换为日期时间 |
pd.to_datetime(df['col']) |
将字符串或数值列转为datetime类型(支持自定义格式)。 |
|
转换为分类数据 |
df['col'].astype('category') |
将列转为分类类型(节省内存,提高性能,适用于有限取值的列如性别、省份)。 |
|
数值格式化 |
df['col'].round(2) |
保留指定小数位数(如2位)。 |
df = pd.read_csv('data/sleep.csv')
# object通常为字符串或混合类型,需检查是否需要转换
print('数据类型')
print(df.dtypes)
# 将sleep_duration从float转为int(丢失小数部分)
print('=='*20)
df['sleep_duration_int'] = df['sleep_duration'].astype('int16')
print(df[['sleep_duration', 'sleep_duration_int']])
# 将gender转为category
print('=='*20)
df['gender_c'] = df['gender'].astype('category')
print(df['gender_c'].dtypes)
# 保留sleep_quality的2位小数
print('=='*20)
df['sleep_quality_rounded'] = df['sleep_quality'].round(2)
# 类型映射
df['性别'] = df['gender'].map({'Male': 0, 'Female': 1})
print(df[['gender', '性别']])
# 输出=============================================
数据类型
person_id int64
gender object
age int64
occupation object
sleep_duration float64
sleep_quality float64
physical_activity_level int64
stress_level int64
bmi_category object
blood_pressure object
heart_rate int64
daily_steps int64
sleep_disorder object
dtype: object
========================================
sleep_duration sleep_duration_int
0 7.4 7
1 4.2 4
2 6.1 6
3 8.3 8
4 9.1 9
.. ... ...
395 4.5 4
396 6.0 6
397 5.3 5
398 11.0 11
399 5.8 5
[400 rows x 2 columns]
========================================
category
========================================
gender 性别
0 Male 0
1 Female 1
2 Male 0
3 Male 0
4 Male 0
.. ... ..
395 Female 1
396 Female 1
397 Female 1
398 Female 1
399 Male 0
[400 rows x 2 columns]常见问题与技巧
处理转换错误:使用errors='coerce'将无效值转为NaN,避免报错:
|
df['age'] = pd.to_numeric(df['age'], errors='coerce') |
内存优化:将数值列从int64转为int32或float32:
|
df['age'] = df['age'].astype('int32') |
布尔类型转换:将字符串(如"Yes"/"No")转为布尔值:
|
df['is_active'] = df['active_flag'].map({'Yes': True, 'No': False}) |
自定义格式化:使用apply实现复杂转换(如百分比):
|
df['score_percent'] = df['score'].apply(lambda x: f"{x*100:.1f}%") |
(4)数据重塑与变形
|
方法/操作 |
语法示例 |
描述 |
|
行列转置 |
df.T |
转置DataFrame(行变列,列变行) |
|
宽表转长表 |
pd.melt(df, id_vars=['id']) |
将多列合并为键值对形式(variable和value列) |
|
长表转宽表 |
df.pivot(index='id', columns='var', values='val') |
将长表转换为宽表(类似Excel数据透视) |
|
分列操作 |
df['col'].str.split(',', expand=True) |
按分隔符拆分字符串为多列 |
- 行列转置
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['NY', 'LA', 'SF']
}
df = pd.DataFrame(data)
print('原始数据:\n', df)
print('\n转置后数据:\n', df.T)
# 输出=========================
原始数据:
Name Age City
0 Alice 25 NY
1 Bob 30 LA
2 Charlie 35 SF
转置后数据:
0 1 2
Name Alice Bob Charlie
Age 25 30 35
City NY LA SF- 宽表转长表
data = {
'ID': [1, 2],
'name':['alice','bob'],
'Math': [90, 85],
'English': [88, 92],
'Science': [95, 89]
}
df = pd.DataFrame(data)
print('原始数据:\n', df)
print('宽表转长表:\n', pd.melt(df, id_vars=['ID', 'name'], var_name='科目', value_name='分数').sort_values('ID'))
# 输出=============================
原始数据:
ID name Math English Science
0 1 alice 90 88 95
1 2 bob 85 92 89
宽表转长表:
ID name 科目 分数
0 1 alice Math 90
2 1 alice English 88
4 1 alice Science 95
1 2 bob Math 85
3 2 bob English 92
5 2 bob Science 89- 长表转宽表
data = {
'ID': [1, 1, 1, 2, 2, 2],
'Subject': ['Math', 'English', 'Science', 'Math', 'English', 'Science'],
'Score': [90, 88, 95, 85, 92, 89]
}
df = pd.DataFrame(data)
print('原始数据:\n', df)
print('转换后数据:\n', df.pivot(index='ID', columns='Subject', values='Score'))
# 输出=====================================
原始数据:
ID Subject Score
0 1 Math 90
1 1 English 88
2 1 Science 95
3 2 Math 85
4 2 English 92
5 2 Science 89
转换后数据:
Subject English Math Science
ID
1 88 90 95
2 92 85 89- 分列操作
按分隔符拆分字符串列,生成多列
data = {
'Full_Name': ['Alice Smith', 'Bob Johnson', 'Charlie Brown']
}
df = pd.DataFrame(data)
print('原始数据:\n', df)
df[['First_Name', 'Last_Name']] = df['Full_Name'].str.split(' ', expand=True)
print("\n拆分后数据:\n", df)
# 输出===============================
原始数据:
Full_Name
0 Alice Smith
1 Bob Johnson
2 Charlie Brown
拆分后数据:
Full_Name First_Name Last_Name
0 Alice Smith Alice Smith
1 Bob Johnson Bob Johnson
2 Charlie Brown Charlie Brown(5)文本数据处理
|
方法/操作 |
语法示例 |
描述 |
|
字符串大小写转换 |
df['col'].str.lower() |
转为小写 |
|
去除空格 |
df['col'].str.strip() |
去除两端空格 |
|
字符串替换 |
df['col'].str.replace('old', 'new') |
替换文本 |
|
正则表达式提取 |
df['col'].str.extract(r'(\d+)') |
提取匹配正则的文本(如数字) |
|
字符串包含检测 |
df['col'].str.contains('abc') |
返回布尔序列,判断是否包含子串 |
- 字符串大小写转换
lower():转小写
upper():转大写
data = {
'Name': ['ALICE', 'Bob', 'CHARLIE']
}
df = pd.DataFrame(data)
print('原始数据:\n', df)
# 转为小写
df['Name_lower'] = df['Name'].str.lower()
# 转为大写
df['Name_upper'] = df['Name'].str.upper()
print('转换后数据:\n', df)
# 输出=================================
原始数据:
Name
0 ALICE
1 Bob
2 CHARLIE
转换后数据:
Name Name_lower Name_upper
0 ALICE alice ALICE
1 Bob bob BOB
2 CHARLIE charlie CHARLIE- 去除空格
strip():去除首尾空格
data = {
'Text': [' Hello ', ' Pandas ', ' Data ']
}
df = pd.DataFrame(data)
print('原始数据:\n', df)
df['Text_stripped'] = df['Text'].str.strip()
print('转换后数据:\n', df)
# 输出=================================
原始数据:
Text
0 Hello
1 Pandas
2 Data
转换后数据:
Text Text_stripped
0 Hello Hello
1 Pandas Pandas
2 Data Data- 字符串替换
replace():替换指定字符串
data = {
'Comment': ['Good!', 'Bad?', 'Okay...']
}
df = pd.DataFrame(data)
print('原始数据:\n', df)
df['Comment_clean'] = df['Comment'].str.replace(r'[!?.]', '',regex=True)
print('转换后数据:\n', df)
# 输出================================
原始数据:
Comment
0 Good!
1 Bad?
2 Okay...
转换后数据:
Comment Comment_clean
0 Good! Good
1 Bad? Bad
2 Okay... Okay- 正则表达式提取
data = {
'Info': ['Age:25', 'Height:170cm', 'Weight:65kg']
}
df = pd.DataFrame(data)
print('原始数据:\n', df)
df['Value'] = df['Info'].str.extract(r'(\d+)')
print('转换后数据:\n', df)
# 输出=================================
原始数据:
Info
0 Age:25
1 Height:170cm
2 Weight:65kg
转换后数据:
Info Value
0 Age:25 25
1 Height:170cm 170
2 Weight:65kg 65- 字符串包含检测
data = {
'Review': ['Great product', 'Not good', 'Excellent service GOOD']
}
df = pd.DataFrame(data)
print('原始数据:\n', df)
# case=False 不区分大小写
df['Is_Positive'] = df['Review'].str.contains('good', case=False)
print('转换后数据:\n', df)
# 输出================================
原始数据:
Review
0 Great product
1 Not good
2 Excellent service GOOD
转换后数据:
Review Is_Positive
0 Great product False
1 Not good True
2 Excellent service GOOD True(6)数据分箱与离散化
|
方法/操作 |
语法示例 |
描述 |
|
等宽分箱 |
pd.cut(df['col'], bins=3) |
将数值列分为等宽区间(如分为低/中/高) |
|
等频分箱 |
pd.qcut(df['col'], q=4) |
将数值列分为等频区间(每箱数据量相同) |
pandas.cut()用于将连续数据(如数值型数据)分割成离散的区间。可以使用cut()来将数据划分为不同的类别或范围,通常用于数据的分箱处理;
参数说明:
X:要分箱的数组或Series,通常是数值型数据。
bins: 切分区间的数值,列表或者整数。如果是整数,则表示将数据均匀地分成多少个区间。如果是列表,则需要指定每个区间的边界。
right:默认True,表示每个区间的右端点是闭区间,即包含右端点。如果设置为False,则左端点为闭区间。
labels:传入一个列表指定每个区间的标签
df = pd.read_csv('data/employees.csv')
df = df.head(10)[['employee_id','salary']]
print('原始数据:\n', df)
print('分组数据:\n', pd.cut(df['salary'], 3).value_counts())
print('分组数据:\n', pd.cut(df['salary'], [1000, 10000, 30000]).value_counts())
print('================================')
df['salary_level'] = pd.cut(df["salary"], bins=3, labels=["low", "medium", "high"])
print(df)
# 等频区间
salary2 = pd.qcut(df["salary"], 3)
print(salary2.value_counts())
# 输出=================================
原始数据:
employee_id salary
0 100 24000.0
1 101 17000.0
2 102 17000.0
3 103 9000.0
4 104 6000.0
5 105 4800.0
6 106 4800.0
7 107 4200.0
8 108 12000.0
9 109 9000.0
分组数据:
salary
(4180.2, 10800.0] 6
(10800.0, 17400.0] 3
(17400.0, 24000.0] 1
Name: count, dtype: int64
分组数据:
salary
(1000, 10000] 6
(10000, 30000] 4
Name: count, dtype: int64
================================
employee_id salary salary_level
0 100 24000.0 high
1 101 17000.0 medium
2 102 17000.0 medium
3 103 9000.0 low
4 104 6000.0 low
5 105 4800.0 low
6 106 4800.0 low
7 107 4200.0 low
8 108 12000.0 medium
9 109 9000.0 low
salary
(12000.0, 24000.0] 4
(4199.999, 6000.0] 3
(6000.0, 12000.0] 3
Name: count, dtype: int64其他转换
set_index():设置行索引,inplace=True:这是一个布尔类型的参数。当设为 True 时,会直接在原 DataFrame上进行修改;若设为 False(默认值),则会返回一个新的 DataFrame,原DataFrame 保持不变。
reset_index: 重置索引
rename:修改行索引名和列名
df = pd.DataFrame({
"age": [20, 30, 40, 10],
"name": ["张三", "李四", "王五", "赵六"],
"id": [101, 102, 103, 104]})
print(df)
# 设置行索引
df.set_index('id', inplace=True)
print('设置行索引:\n', df)
# 重置索引
df.reset_index(inplace=True)
print('重置索引:\n', df)
# 修改行索引名和列名 个别修改
df.rename(index={0: 'A', 1: 'B'}, columns={'age': '年龄'}, inplace=True)
print('个别修改:\n', df)
# 重新赋值 批量修改
df.index = ['a', 'b', 'c', 'd']
df.columns = ['编号','年龄','姓名']
print('批量修改:\n',df)
# #添加列 通过 df[“列名”] 添加列。
df['phone'] = ['0556', '0557', '0558', '0559']
print('通过 df[“列名”] 添加列: \n', df)
# 删除列 通过 df.drop(“列名”, axis=1) 删除,也可是删除行 axis=0
df.drop('phone', axis=1, inplace=True)
print('删除列: \n', df)
# 通过 del df[“列名”] 删除
del df['编号']
print('del df[“列名”] 删除: \n', df)
#插入列 通过 insert(loc, column, value) 插入。该方法没有inplace参数,直接在原数据上修改。
df.insert(loc=1, column='性别', value= ['f', 'm', 'm', 'f'])
print('通过 insert插入: \n',df)
# 输出====================================
age name id
0 20 张三 101
1 30 李四 102
2 40 王五 103
3 10 赵六 104
设置行索引:
age name
id
101 20 张三
102 30 李四
103 40 王五
104 10 赵六
重置索引:
id age name
0 101 20 张三
1 102 30 李四
2 103 40 王五
3 104 10 赵六
个别修改:
id 年龄 name
A 101 20 张三
B 102 30 李四
2 103 40 王五
3 104 10 赵六
批量修改:
编号 年龄 姓名
a 101 20 张三
b 102 30 李四
c 103 40 王五
d 104 10 赵六
通过 df[“列名”] 添加列:
编号 年龄 姓名 phone
a 101 20 张三 0556
b 102 30 李四 0557
c 103 40 王五 0558
d 104 10 赵六 0559
删除列:
编号 年龄 姓名
a 101 20 张三
b 102 30 李四
c 103 40 王五
d 104 10 赵六
del df[“列名”] 删除:
年龄 姓名
a 20 张三
b 30 李四
c 40 王五
d 10 赵六
通过 insert插入:
年龄 性别 姓名
a 20 f 张三
b 30 m 李四
c 40 m 王五
d 10 f 赵六7、时间数据的处理
Timestamp 是 pandas 对 datetime64 数据类型的一个封装。datetime64 是 NumPy 中的一种数据类型,用于表示日期和时间,而 pandas 基于 datetime64 构建了 Timestamp 类,以便更方便地在 pandas 的数据结构(如 DataFrame 和 Series)中处理日期时间数据。当 pd.to_datetime 接收单个日期时间值时,会返回 Timestamp 对象
(1)时间戳timestamp
常用属性:
| 属性 | 说明 |
| year | 获取年 |
| month | 获取月 |
| day | 获取日 |
| hour | 获取小时 |
| minute | 获取分钟 |
| second | 获取秒 |
|
microsecond |
获取微秒 |
| quarter | 获取季度 |
| is_month_end | 是否为月末 |
| is_month_start | 是否为月初 |
| is_year_end | 是否为年底 |
| is_year_strart | 是否未年初 |
常用方法:
| 方法 | 说明 |
| day_name() | 获取星期 |
| to_period |
获取统计周期 |
to_period() 方法的freq参数:
- "D":按天周期,例如 2024-01-01 会转换为 2024-01-01 这个天的周期。
- "W":按周周期,通常以周日作为一周的结束,比如日期落在某一周内,就会转换为该周的周期表示。
- "M":按月周期,像 2024-05-15 会转换为 2024-05。
- "Q":按季度周期,一年分为四个季度,日期会转换到对应的季度周期,例如 2024Q2 。
- "A" 或 "Y":按年周期,如 2024-07-20 会转换为 2024 。
d = pd.Timestamp('2025-12-26 17:50:10.14563')
print(type(d))
# 属性
print('年:', d.year)
print('月:', d.month)
print('日:', d.day)
print('时:', d.hour)
print('分:', d.minute)
print('秒:', d.second)
print('毫秒:', d.microsecond)
print('季度:', d.quarter)
print('是否月初:', d.is_month_start)
print('是否月末:', d.is_month_end)
print('是否年初:', d.is_year_start)
print('是否年末:', d.is_year_end)
# 方法
print('周:', d.day_name())
print('转为年:', d.to_period('Y'))
print('转为季度:', d.to_period('Q'))
print('转为月:', d.to_period('M'))
print('转为周:', d.to_period('W'))
# 输出================================
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
年: 2025
月: 12
日: 26
时: 17
分: 50
秒: 10
毫秒: 145630
季度: 4
是否月初: False
是否月末: False
是否年初: False
是否年末: False
周: Friday
转为年: 2025
转为季度: 2025Q4
转为月: 2025-12
转为周: 2025-12-22/2025-12-28(2)日期数据转换
| 方法 | 说明 |
| to_datetime() | 字符串转为日期类型 |
# 字符串字段转换为日期类型
a1 = pd.to_datetime('2025-07-01')
a2 = pd.to_datetime('20250409')
a3 = pd.to_datetime('2025/04/13')
a4 = pd.to_datetime('2025-07')
print(a1)
print(a2)
print(a3)
print(a4)
print(type(a1))
print('===============================')
# dateFrame中的日期转换
df = pd.DataFrame({
'sales':[100,50,40],
'date':['2025-01-01','2023-03-02','2025-03-09']
})
df['datetime'] = pd.to_datetime(df['date'])
print(type(df['datetime'].dt))
df['week'] = df['datetime'].dt.day_name()
print(df)
# 输出================================
2025-07-01 00:00:00
2025-04-09 00:00:00
2025-04-13 00:00:00
2025-07-01 00:00:00
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
===============================
<class 'pandas.core.indexes.accessors.DatetimeProperties'>
sales date datetime week
0 100 2025-01-01 2025-01-01 Wednesday
1 50 2023-03-02 2023-03-02 Thursday
2 40 2025-03-09 2025-03-09 Sundaydf = pd.read_csv('data/weather.csv')
print(df['date'].head(5))
print('=========================')
print(pd.to_datetime(df['date'].head(5)))
# 在加载数据时也可以通过parse_dates参数将指定列解析为datetime64。
df = pd.read_csv('data/weather.csv', parse_dates=['date'])
df.info()
print(df['date'].dt.day_name().head())
#输出=============================
0 2012-01-01
1 2012-01-02
2 2012-01-03
3 2012-01-04
4 2012-01-05
Name: date, dtype: object
=========================
0 2012-01-01
1 2012-01-02
2 2012-01-03
3 2012-01-04
4 2012-01-05
Name: date, dtype: datetime64[ns]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1461 entries, 0 to 1460
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 1461 non-null datetime64[ns]
1 precipitation 1461 non-null float64
2 temp_max 1461 non-null float64
3 temp_min 1461 non-null float64
4 wind 1461 non-null float64
5 weather 1461 non-null object
dtypes: datetime64[ns](1), float64(4), object(1)
memory usage: 68.6+ KB
0 Sunday
1 Monday
2 Tuesday
3 Wednesday
4 Thursday
Name: date, dtype: object(3)日期数据作为索引
将datetime64类型的数据设置为索引,得到的就是DatetimeIndex
df = pd.read_csv('data/weather.csv', parse_dates=['date'])
df.set_index('date', inplace=True)
# 使用时间进行切片取值
print(df.loc['2015-06-01':'2015-06-10'])
print('=====================')
print(df.loc['2015-06'])
# 通过between_time()和at_time()获取某些时刻的数据
print('=====================')
print(df.between_time("9:00", "11:00"))
df.at_time("3:33")
# 输出=============================
precipitation temp_max temp_min wind weather
date
2015-06-01 4.6 16.1 11.7 3.4 rain
2015-06-02 0.5 17.8 12.8 5.0 rain
2015-06-03 0.0 20.0 11.7 3.0 sun
2015-06-04 0.0 22.8 11.7 3.9 sun
2015-06-05 0.0 26.7 12.8 4.3 sun
2015-06-06 0.0 29.4 13.3 2.6 sun
2015-06-07 0.0 31.1 15.6 3.2 sun
2015-06-08 0.0 30.6 14.4 3.5 sun
2015-06-09 0.0 28.9 14.4 2.7 sun
2015-06-10 0.0 25.6 11.1 3.0 sun
=====================
precipitation temp_max temp_min wind weather
date
2015-06-01 4.6 16.1 11.7 3.4 rain
2015-06-02 0.5 17.8 12.8 5.0 rain
2015-06-03 0.0 20.0 11.7 3.0 sun
2015-06-04 0.0 22.8 11.7 3.9 sun
2015-06-05 0.0 26.7 12.8 4.3 sun
2015-06-06 0.0 29.4 13.3 2.6 sun
2015-06-07 0.0 31.1 15.6 3.2 sun
2015-06-08 0.0 30.6 14.4 3.5 sun
2015-06-09 0.0 28.9 14.4 2.7 sun
2015-06-10 0.0 25.6 11.1 3.0 sun
2015-06-11 0.0 24.4 11.1 3.5 sun
2015-06-12 0.0 20.0 11.7 2.3 sun
2015-06-13 0.0 23.9 9.4 2.6 sun
2015-06-14 0.0 27.8 11.7 3.7 sun
2015-06-15 0.0 30.0 16.1 3.5 drizzle
2015-06-16 0.0 22.8 11.1 3.0 sun
2015-06-17 0.0 25.0 11.1 3.1 sun
2015-06-18 0.0 24.4 13.9 3.0 sun
2015-06-19 0.5 23.9 13.3 3.2 rain
2015-06-20 0.0 25.0 12.8 4.3 sun
2015-06-21 0.0 25.6 13.9 3.4 sun
2015-06-22 0.0 25.0 12.8 2.4 sun
2015-06-23 0.0 26.1 11.7 2.4 sun
2015-06-24 0.0 25.6 16.1 2.6 sun
2015-06-25 0.0 30.6 15.6 3.0 sun
2015-06-26 0.0 31.7 17.8 4.7 sun
2015-06-27 0.0 33.3 17.2 3.9 sun
2015-06-28 0.3 28.3 18.3 2.1 rain
2015-06-29 0.0 28.9 17.2 2.7 sun
2015-06-30 0.0 30.6 15.0 3.4 fog
=====================
Empty DataFrame
Columns: [precipitation, temp_max, temp_min, wind, weather]
Index: [](4)时间间隔timedelta
当用一个日期减去另一个日期,返回的结果是timedelta64类型。
d1 = pd.Timestamp( "2015-05-01 09:08:07.123456" )
d2 = pd.Timestamp( "2015-05-31 09:23:07.123456" )
print('间隔天数:', d2 - d1)
print(type(d1))
print(type(d2-d1))
print('========================')
# 将timedelta64类型的数据设置为索引,得到的就是TimedeltaIndex
df = pd.read_csv("data/weather.csv", parse_dates=['date'])
df['timedelta'] = df['date'] - df['date'][0]
df.set_index('timedelta', inplace=True)
print(df.loc['0 days':'5 days'])
# 输出==============================
间隔天数: 30 days 00:15:00
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
<class 'pandas._libs.tslibs.timedeltas.Timedelta'>
========================
date precipitation temp_max temp_min wind weather
timedelta
0 days 2012-01-01 0.0 12.8 5.0 4.7 drizzle
1 days 2012-01-02 10.9 10.6 2.8 4.5 rain
2 days 2012-01-03 0.8 11.7 7.2 2.3 rain
3 days 2012-01-04 20.3 12.2 5.6 4.7 rain
4 days 2012-01-05 1.3 8.9 2.8 6.1 rain
5 days 2012-01-06 2.5 4.4 2.2 2.2 rain(5)时间序列
- date_range()通过开始日期、结束日期和频率代码(可选)创建一个有规律的日期序列,默认的频率是天。
print(pd.date_range(start='2015-05-01', end='2015-05-03', freq='D'))
# 输出================================
DatetimeIndex(['2015-05-01', '2015-05-02', '2015-05-03'], dtype='datetime64[ns]', freq='D')- 日期范围不一定非是开始时间与结束时间,也可以是开始时间与周期数periods
print(pd.date_range(start='2015-05-01', periods=5))
# 输出========================
DatetimeIndex(['2015-05-01', '2015-05-02', '2015-05-03', '2015-05-04',
'2015-05-05'],
dtype='datetime64[ns]', freq='D')- 可以通过freq参数设置时间频率,默认值是D。此处改为h,按小时变化的时间戳
时间频率代码与说明:
|
代码 |
说明 |
|
D |
天(calendar day,按日历算,含双休日) |
|
B |
天(business day,仅含工作日) |
|
W |
周(weekly) |
|
ME / M |
月末(month end) |
|
BME |
月末(business month end,仅含工作日) |
|
MS |
月初(month start) |
|
BMS |
月初(business month start,仅含工作日) |
|
QE / Q |
季末(quarter end) |
|
BQE |
季末(business quarter end,仅含工作日) |
|
QS |
季初(quarter start) |
|
BQS |
季初(business quarter start,仅含工作日) |
|
YE / Y |
年末(year end) |
|
BYE |
年末(business year end,仅含工作日) |
|
YS |
年初(year start) |
|
BYS |
年初(business year start,仅含工作日) |
|
h |
小时(hours) |
|
bh |
小时(business hours,工作时间) |
|
min |
分钟(minutes) |
|
s |
秒(seconds) |
|
ms |
毫秒(milliseonds) |
|
us |
微秒(microseconds) |
|
ns |
纳秒(nanoseconds) |
print(pd.date_range("2015-07-03", periods=5, freq="W"))
# 输出========================================
DatetimeIndex(['2015-07-05', '2015-07-12', '2015-07-19', '2015-07-26',
'2015-08-02'],
dtype='datetime64[ns]', freq='W-SUN')可以在频率代码后面加三位月份缩写字母来改变季、年频率的开始时间。
- QE-JAN、BQE-FEB、QS-MAR、BQS-APR等
- YE-JAN、BYE-FEB、YS-MAR、BYS-APR等
print(pd.date_range('2025-12-01', periods=3, freq='QE-JAN'))
# 输出=================================
DatetimeIndex(['2026-01-31', '2026-04-30', '2026-07-31'], dtype='datetime64[ns]', freq='QE-JAN')也可以在后面加三位星期缩写字母来改变一周的开始时间。
- W-SUN、W-MON、W-TUE、W-WED等
print(pd.date_range('2025-12-01', periods=3, freq='W-SUN'))
# 输出=========================================
DatetimeIndex(['2025-12-07', '2025-12-14', '2025-12-21'], dtype='datetime64[ns]', freq='W-SUN')可以将频率组合起来创建的新的周期。例如,可以用小时(h)和分钟(min)的组合来实现2小时30分钟。
print(pd.date_range('2025-10-10', periods=5, freq='2h30min'))
# 输出========================================
DatetimeIndex(['2025-10-10 00:00:00', '2025-10-10 02:30:00',
'2025-10-10 05:00:00', '2025-10-10 07:30:00',
'2025-10-10 10:00:00'],
dtype='datetime64[ns]', freq='150min')(6)重新采样
处理时间序列数据时,经常需要按照新的频率(更高频率、更低频率)对数据进行重新采样。可以通过resample()方法解决这个问题。resample()方法以数据累计为基础,会将数据按指定的时间周期进行分组,之后可以对其使用聚合函数。
df = pd.read_csv('data/weather.csv', parse_dates=['date'])
df.info()
df.set_index('date', inplace=True)
print('================================')
print(df[['temp_max', 'temp_min']].resample('YS').mean())
# 输出===================================
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1461 entries, 0 to 1460
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 1461 non-null datetime64[ns]
1 precipitation 1461 non-null float64
2 temp_max 1461 non-null float64
3 temp_min 1461 non-null float64
4 wind 1461 non-null float64
5 weather 1461 non-null object
dtypes: datetime64[ns](1), float64(4), object(1)
memory usage: 68.6+ KB
================================
temp_max temp_min
date
2012-01-01 15.276776 7.289617
2013-01-01 16.058904 8.153973
2014-01-01 16.995890 8.662466
2015-01-01 17.427945 8.8356168、数据分析与统计
统计函数:
|
方法 |
说明 |
|
sum() |
求和 |
|
mean() |
平均值 |
|
min() |
最小值 |
|
max() |
最大值 |
|
var() |
方差 |
|
std() |
标准差 |
|
median() |
中位数 |
|
quantile() |
指定位置的分位数,如quantile(0.5) |
|
describe() |
常见统计信息 |
|
size() |
所有元素的个数 |
|
count() |
非空元素的个数 |
|
first |
第一行 |
|
last |
最后一行 |
|
nth |
第n行 |
(1)分组聚合
方法:
df.groupby("分组字段")["要聚合的字段"].聚合函数()
df.groupby(["分组字段", "分组字段2", ...])[["要聚合的字段", "要聚合的字段2", ...]].聚合函数()
通过groups属性查看分组结果,返回一个字典,字典的键是分组的标签,值是属于该组的所有索引的列表。
df = pd.read_csv('data/employees.csv')
print(df.groupby('department_id').groups)
# 输出=====================
{10.0: [100], 20.0: [101, 102], 30.0: [14, 15, 16, 17, 18, 19], 40.0: [103], ... , 100.0: [8, 9, 10, 11, 12, 13], 110.0: [105, 106]}- 通过get_group()方法获取分组
print(df.groupby('department_id').get_group(20))
# 输出================================
employee_id first_name last_name email phone_number job_id \
101 201 Michael Hartstein MHARTSTE 515.123.5555 MK_MAN
102 202 Pat Fay PFAY 603.123.6666 MK_REP
salary commission_pct manager_id department_id
101 13000.0 NaN 100.0 20.0
102 6000.0 NaN 201.0 20.0 - 按列取值并聚合计算
print(df.groupby('department_id')['salary'].mean())
# 输出=================================
department_id
10.0 4400.000000
20.0 9500.000000
30.0 4150.000000
40.0 6500.000000
50.0 3475.555556
60.0 5760.000000
70.0 10000.000000
80.0 8955.882353
90.0 19333.333333
100.0 8600.000000
110.0 10150.000000
Name: salary, dtype: float64- 按多字段分组
print(df.groupby(['department_id', 'job_id'])[['salary',"commission_pct"]].mean())
# 输出===============
salary commission_pct
department_id job_id
10.0 AD_ASST 4400.000000 NaN
20.0 MK_MAN 13000.000000 NaN
MK_REP 6000.000000 NaN
30.0 PU_CLERK 2780.000000 NaN
PU_MAN 11000.000000 NaN
40.0 HR_REP 6500.000000 NaN
50.0 SH_CLERK 3215.000000 NaN
ST_CLERK 2785.000000 NaN
ST_MAN 7280.000000 NaN
60.0 IT_PROG 5760.000000 NaN
70.0 PR_REP 10000.000000 NaN
80.0 SA_MAN 12200.000000 0.300000
SA_REP 8396.551724 0.212069
90.0 AD_PRES 24000.000000 NaN
AD_VP 17000.000000 NaN
100.0 FI_ACCOUNT 7920.000000 NaN
FI_MGR 12000.000000 NaN
110.0 AC_ACCOUNT 8300.000000 NaN
AC_MGR 12000.000000 NaN- 可通过reset_index()方法重置索引,也可以在分组的时候通过as_index = False参数(默认是True)重置索引
# salary_mean = df.groupby(['department_id', 'job_id'])[['salary',"commission_pct"]].mean()
# salary_mean.reset_index(inplace=True)
salary_mean = df.groupby(['department_id', 'job_id'], as_index=False)[['salary',"commission_pct"]].mean()
print(salary_mean)
# 输出==============================
department_id job_id salary commission_pct
0 10.0 AD_ASST 4400.000000 NaN
1 20.0 MK_MAN 13000.000000 NaN
2 20.0 MK_REP 6000.000000 NaN
3 30.0 PU_CLERK 2780.000000 NaN
4 30.0 PU_MAN 11000.000000 NaN
5 40.0 HR_REP 6500.000000 NaN
6 50.0 SH_CLERK 3215.000000 NaN
7 50.0 ST_CLERK 2785.000000 NaN
8 50.0 ST_MAN 7280.000000 NaN
9 60.0 IT_PROG 5760.000000 NaN
10 70.0 PR_REP 10000.000000 NaN
11 80.0 SA_MAN 12200.000000 0.300000
12 80.0 SA_REP 8396.551724 0.212069
13 90.0 AD_PRES 24000.000000 NaN
14 90.0 AD_VP 17000.000000 NaN
15 100.0 FI_ACCOUNT 7920.000000 NaN
16 100.0 FI_MGR 12000.000000 NaN
17 110.0 AC_ACCOUNT 8300.000000 NaN
18 110.0 AC_MGR 12000.000000 NaN(2)一次统计多个值
- 可以通过agg()或aggregate()进行更复杂的操作,如一次计算多个统计值
print(df.groupby('department_id')['salary'].aggregate(['max', 'min', 'mean']))
# 输出=================================
max min mean
department_id
10.0 4400.0 4400.0 4400.000000
20.0 13000.0 6000.0 9500.000000
30.0 11000.0 2500.0 4150.000000
40.0 6500.0 6500.0 6500.000000
50.0 8200.0 2100.0 3475.555556
60.0 9000.0 4200.0 5760.000000
70.0 10000.0 10000.0 10000.000000
80.0 14000.0 6100.0 8955.882353
90.0 24000.0 17000.0 19333.333333
100.0 12000.0 6900.0 8600.000000
110.0 12000.0 8300.0 10150.000000- 可以在agg()中传入字典,对多个列计算不同的统计值
print(df.groupby("department_id").agg({"job_id": "nunique", "salary": "sum"}))
# 输出================================
job_id salary
department_id
10.0 1 4400.0
20.0 2 19000.0
30.0 2 24900.0
40.0 1 6500.0
50.0 3 156400.0
60.0 1 28800.0
70.0 1 10000.0
80.0 2 304500.0
90.0 2 58000.0
100.0 2 51600.0
110.0 2 20300.0- 可以在agg()后通过rename()对统计后的列重命名
print(df.groupby("department_id").agg({"job_id": "nunique", "salary": "sum"}).rename(columns= {'job_id': '工种', 'salary': '薪资总和'}))
# 输出===============================
工种 薪资总和
department_id
10.0 1 4400.0
20.0 2 19000.0
30.0 2 24900.0
40.0 1 6500.0
50.0 3 156400.0
60.0 1 28800.0
70.0 1 10000.0
80.0 2 304500.0
90.0 2 58000.0
100.0 2 51600.0
110.0 2 20300.0- 可以向agg()中传入自定义函数进行计算
def f(x):
"""统计每个部门员工last_name的首字母"""
result = set()
for i in x:
result.add(i[0])
return result
print(df.groupby("department_id")["last_name"].agg(f))
# 输出=======================================
department_id
10.0 {W}
20.0 {H, F}
30.0 {H, K, B, C, R, T}
40.0 {M}
50.0 {S, D, W, G, B, F, R, A, P, V, J, K, N, O, M, ...
60.0 {H, E, L, A, P}
70.0 {B}
80.0 {S, D, Z, G, B, F, R, A, P, H, V, J, K, M, O, ...
90.0 {K, D}
100.0 {U, S, G, F, C, P}
110.0 {H, G}
Name: last_name, dtype: object(3)分组转换
聚合操作返回的是对组内全量数据缩减过的结果,而转换操作会返回一个新的全量数据。数据经过转换之后,其形状与原来的输入数据是一样的。
通过transform()将每一组的样本数据减去各组的均值,实现数据标准化
import numpy as np
# 随机挑选30条数据
na_index = pd.Series(df.index.tolist()).sample(30)
# 将这30条数据的salary设置为缺失值
df.loc[na_index, "salary"] = pd.NA
# 查看每组数据总数与非空数据数
print(df.groupby("department_id")["salary"].agg(["size", "count"]))
print('==='*10)
def fill_missing(x):
# 使用平均值填充,如果平均值也为NaN,用0填充
if np.isnan(x.mean()):
return 0
return x.fillna(x.mean())
df["salary"] = df.groupby("department_id")["salary"].transform(fill_missing)
# 查看每组数据总数与非空数据数
print(df.groupby("department_id")["salary"].agg(["size", "count"]))
# 输出===================================
size count
department_id
10.0 1 1
20.0 2 1
30.0 6 3
40.0 1 0
50.0 45 21
60.0 5 3
70.0 1 0
80.0 34 18
90.0 3 3
100.0 6 0
110.0 2 1
==============================
size count
department_id
10.0 1 1
20.0 2 2
30.0 6 6
40.0 1 1
50.0 45 45
60.0 5 5
70.0 1 1
80.0 34 34
90.0 3 3
100.0 6 6
110.0 2 2(4)分组过滤
过滤操作可以让我们按照分组的属性丢弃若干数据。
# 按department_id分组,过滤掉commission_pct包含空值的分组
commission_pct_filter = df.groupby("department_id").filter(
lambda x: x["commission_pct"].notnull().all()
)
print(commission_pct_filter[['department_id', 'commission_pct']])
# 输出========================
department_id commission_pct
45 80.0 0.40
46 80.0 0.30
47 80.0 0.30
48 80.0 0.30
...
...
71 80.0 0.15
72 80.0 0.15
73 80.0 0.10
74 80.0 0.30
75 80.0 0.25
76 80.0 0.20
77 80.0 0.20
79 80.0 0.109、案例
(1)对企鹅数据集进行操作
import pandas as pd
import numpy as np
# 导入数据集
penguins = pd.read_csv('data/penguins.csv')
# 获取前5行数据查看
print('获取前5行数据查看: \n', penguins.head())
# 查看数据集信息
print('查看数据集信息: \n')
display(penguins.info())
# 检查缺失值
print('检查缺失值\n', penguins.isnull().sum())
# 处理缺失值 - 删除含有缺失值的行
penguins_clean = penguins.dropna()
# 将性别列转换为类别类型
print('性别列数据类型: ',penguins_clean['sex'].dtype)
penguins_clean['sex'] = penguins_clean['sex'].astype('category', )
print('转换后性别列数据类型: ',penguins_clean['sex'].dtype)
# 创建新特征:喙长与喙深的比值
penguins_clean['bill_ratio'] = penguins_clean['bill_length_mm'] / penguins_clean['bill_depth_mm']
# 按物种分组计算平均特征值
species_stats = penguins_clean.groupby('species').agg({
'bill_length_mm': 'mean',
'bill_depth_mm': 'mean',
'flipper_length_mm': 'mean',
'body_mass_g': 'mean',
'bill_ratio': 'mean'
}).round(2)
print("\n不同物种的平均特征值:\n", species_stats)
# 将体重分为低、中、高三个等级
pd.cut(penguins_clean['body_mass_g'], bins=3, labels=['低', '中', '高'])
# 按岛屿和性别分组分析
island_sex_stats = penguins_clean.groupby(['sex']).agg({
'body_mass_g': ['mean', 'count']
})
print("\n按性别分组的统计数据:")
print(island_sex_stats)更多推荐



 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)