
Pandas核心知识点大全:从入门到进阶,这一篇就够了!(建议收藏)
·
数据分析师必备的Pandas cheat sheet,效率提升100%
在数据分析和机器学习的领域,Pandas无疑是Python中最核心、最常用的库之一。无论是数据清洗、转换、聚合还是可视化,都离不开它。今天,我将为大家系统性地梳理Pandas的核心知识点,并附上大量代码示例。无论是新手入门还是老手查漏补缺,这篇文章都值得你点赞收藏,方便日后随时翻阅!
一、Pandas两大数据结构:Series和DataFrame
Pandas的基石,必须先理解它们。
1. Series - 带标签的一维数组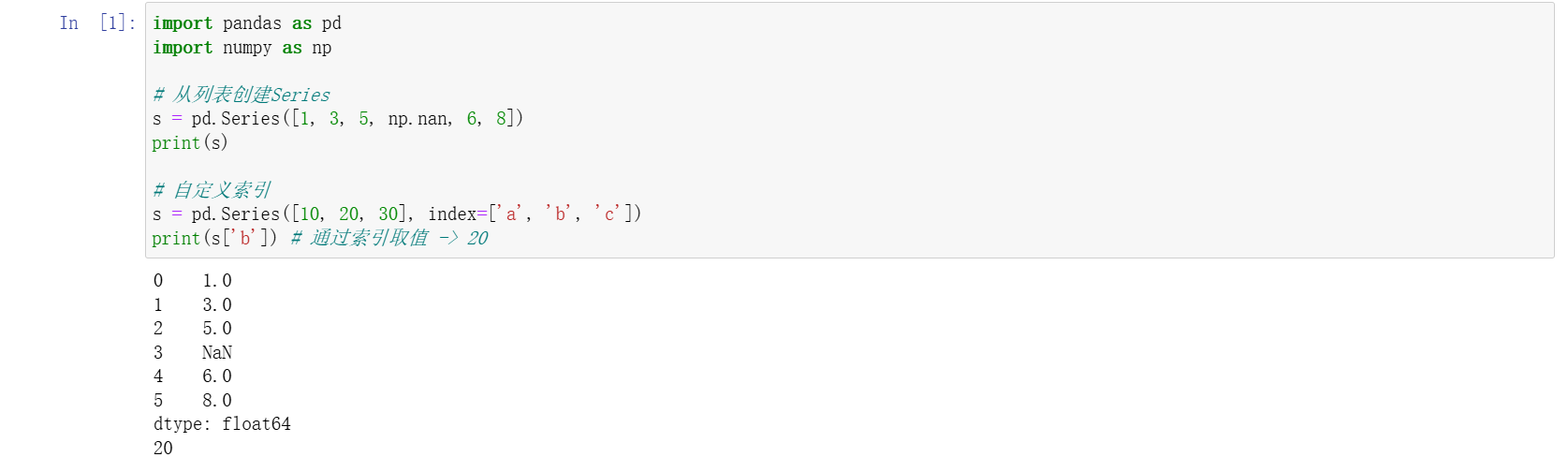
核心特点:索引自动对齐,在进行数据计算时非常重要。
2. DataFrame - 二维表格,核心中的核心
可以看作是一个由Series组成的字典。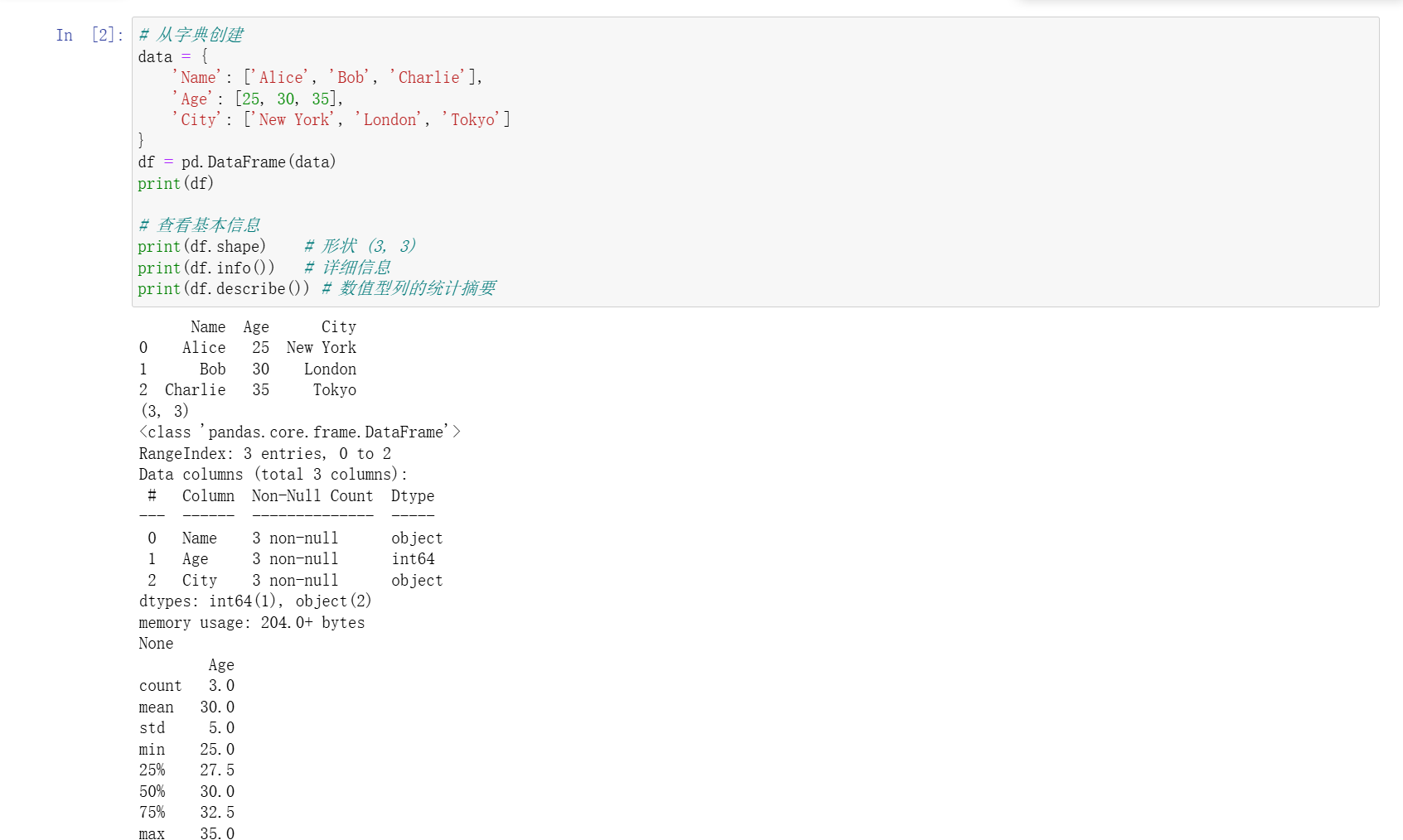
二、数据读取与导出(I/O操作)
这是所有数据分析的第一步。
三、数据查看与筛选(重中之重!)
1. 查看数据
2. 数据筛选:loc 和 iloc (最容易混淆的点!)
-
loc:基于标签进行选择。 -
iloc:基于整数位置进行选择。 💡 避坑指南:
💡 避坑指南:loc的切片是闭区间[start:end],而iloc是开区间[start:end),和Python列表一样!四、数据处理与清洗(实战核心)
1. 处理缺失值 NaN
 2. 处理重复值
2. 处理重复值 3. 数据类型转换
3. 数据类型转换 4. 重命名列
4. 重命名列
五、数据变形与分组(进阶操作)
1. 分组聚合
groupby这是Pandas最强大的功能之一。

2. 数据透视表
pivot_table像Excel数据透视表一样方便。
 3. 表的合并
3. 表的合并 merge/concat
六、常用函数与技巧(效率神器)
1.
apply函数:对数据应用自定义函数 2.
2. value_counts:快速计数 3.
3. sort_values:排序 4.
4. str访问器:处理字符串列
七、时间序列处理(特色功能)
Pandas在时间序列分析上非常强大。

总结
为了让大家更好地记忆,我将最核心的操作总结为一张图:
操作类别 核心函数/方法 一句话说明 数据读取 read_csv,read_excel从文件加载数据 数据查看 head,info,describe快速了解数据概况 数据筛选 loc[],iloc[],query()精确选取目标数据 数据清洗 isnull(),dropna(),fillna()处理缺失值和异常 数据变形 groupby,pivot_table,merge聚合、透视、合并数据 数据应用 apply,map,value_counts应用函数和快速统计 以上就是Pandas在实际工作中最常用、最核心的知识点总结。熟练掌握这些,你就能解决90%以上的数据处理任务。希望这篇干货能对你的学习和工作有所帮助!
如果觉得有用,请不要吝啬你的【点赞👍】和【收藏⭐】,这对我的是巨大的鼓励!
有任何问题,欢迎在评论区留言交流~ 我也会分享更多数据分析的实战技巧,记得关注我哦!
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)