
2023年第四届MathorCup高校数学建模挑战赛——大数据竞赛-B题 电商零售商家需求预测及库存优化问题-基于贝叶斯优化CNN-LSTM的电商零售商家需求预测
基于贝叶斯优化CNN-LSTM的电商零售商家需求预测及库存优化问题
摘 要
在电商平台上,上千个商家将商品货物放在配套的仓库。针对这些货物,电商平台需要采用科学的管理手段和智能决策,通过大数据智能驱动的供应链来降低库存成本、提高库存周转率、降低滞销风险,并确保商品按时履约。基于历史出货量数据,经行了一下的研究。
首先,对附件所提供的数据进行预处理,包括合并和去重,最终得到331,336条数据。进行了缺失值处理,发现无缺失值。针对异常值处理的考虑,决定在聚类后针对每个类别进行更精细化的异常值检验数据标准化。数据转码部分主要针对商家分类和仓库区域进行了转码操作,将其转为相应的数字编码。这样处理后的数据能够更好地用于后续的分析和建模工作。
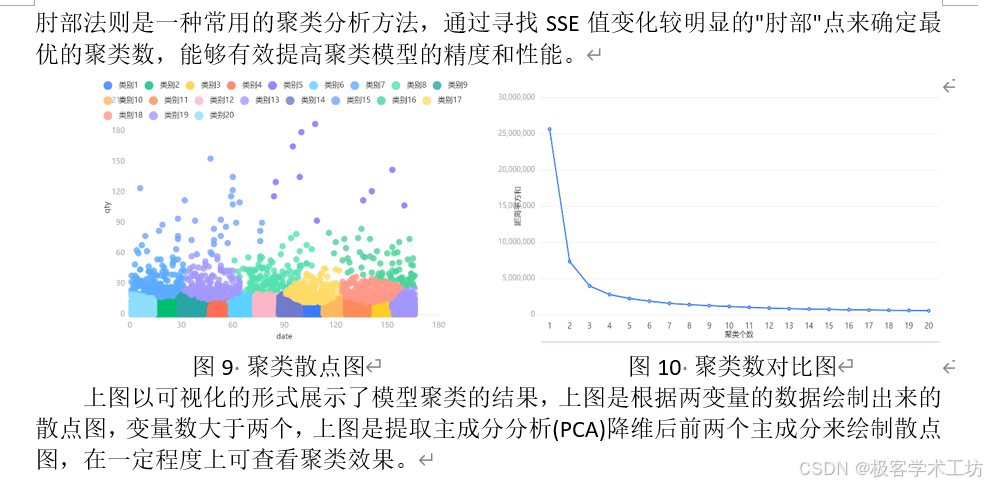
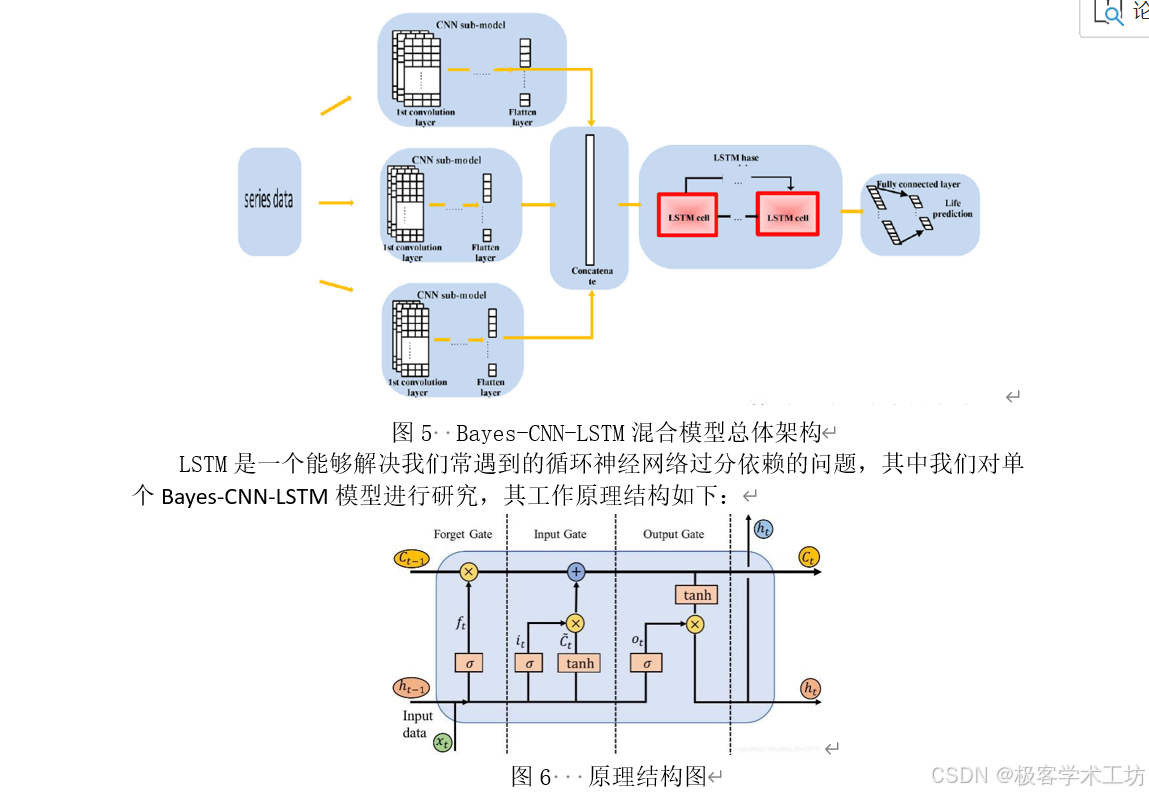
根据问题一,我们需要预测不同商家-产品-仓库组合的未来需求量。首先,由于不同组合之间存在复杂的关系,我们对汇总的数据进行特征提取。这些特征包括平均需求量、需求量的标准差、季节性模式的强度、趋势模式的强度、最大需求量和最小需求量。通过这些特征,我们可以描述时间序列数据的中心倾向、变动性、季节性和趋势等方面的信息。然后,我们使用K-means聚类算法对数据进行分析。在得到聚类结果后,针对每个聚类类别,利用历史数据的特征和趋势,来预测未来的需求量。建立了相应的预测模型。我们考虑了使用SARIMA时间序列模型进行预测,同时也使用贝叶斯优化CNN-LSTM混合模型进行预测。为了评估模型的预测性能,我们使用1-wmape、均方根误差(RMSE)、MAPE和确定系数(R-squared)等指标进行评价。通过交叉验证的方法,更准确地评估不同预测模型的性能,并选择表现最好的模型进行预测,对最终的结果进行时间序列图等可视化,保存在结果表1-预测结果表.xlsx。
对于问题二,在数据预处理阶段,我们对附件五和附件一合并的数据集进行了准确的数据清洗、缺失值处理和异常值检测。接下来,我们应用k-means算法进行聚类分析,自动确定最适合的聚类数目,并发现数据中的潜在模式和结构。然后,我们使用问题一构建好的Bayes-CNN-LSTM混合模型,结合贝叶斯网络、卷积神经网络和长短期记忆网络的优势,对新出现的预测维度进行预测。通过模型参数和历史数据,预测了未来一段时间内的销售量,帮助企业做出合理的生产和供应计划,以满足市场需求的变化。通过结果表2的展示,我们可以看到针对不同商家、仓库和商品维度的预测结果。
根据附件1中的历史出货量表数据,以商家+仓库+商品维度为索引,并按日期排序,可以得到每个维度在每天的出货量。通过使用附件2-4中的商家、仓库和商品信息,对历史出货量表进行补充,例如添加分类、品牌等信息,更好地预测和管理供应链中的库存。同时,参考附件6中给出的历史需求量数据,对数据集进行训练和学习。针对历史出货量数据,可以进行时间序列特征提取,包括季节性、趋势性、周期性等,加入其他特征,如商家、仓库和商品的属性信息,以提高模型的准确性和泛化能力。将历史数据按一定比例划分为训练集和验证集,采用贝叶斯优化算法确定CNN-LSTM模型的,使用最佳超参数的模型对验证集进行需求量预测,结合供应链管理的实际需求,可以得到准确可靠的预测结果和有效的库存管理建议。需要根据具体情况进行调整和优化,以提高模型的精度和可靠性。
关键词 K-means聚类模型、SARIMA时间序列模型的构建、贝叶斯优化CNN-LSTM时间序列预测、商家需求预测
目录
一、问题重述...................................................................................... 1
二、 问题分析.................................................................................... 1
三、模型假设...................................................................................... 2
四、定义与符号说明.......................................................................... 2
五、模型的建立与求解...................................................................... 2
5.1数据预处理.................................................................................. 2
5.1.1 数据合并.............................................................................. 2
5.1.2数据清洗............................................................................... 3
5.1.3数据转码............................................................................... 3
5.2问题1的模型建立与求解............................................................ 3
5.2.1 数据探索性分析................................................................... 3
5.2.2 K-means聚类模型的构建..................................................... 6
5.2.3 SARIMA时间序列模型的构建................................................ 8
5.2.4贝叶斯优化CNN-LSTM时间序列预测模型建立.................... 10
5.2.5 评价模型的预测性能.......................................................... 13
5.2.6模型的求解......................................................................... 14
5.3问题2的模型建立与求解.......................................................... 15
5.3.1 模型的建立........................................................................ 15
5.3.2问题2模型的求解.............................................................. 16
5.4问题3的模型建立与求解.......................................................... 17
5.4.1 模型的建立........................................................................ 17
5.4.2模型的求解......................................................................... 18
六.模型的评价及优化.................................................................... 20
6.1 模型的优点............................................................................... 20
6.2 模型的缺点............................................................................... 20
6.3 模型的推广............................................................................... 20
参考文献............................................................................................ 21
一、问题重述
电商平台上有很多商家,他们将商品存放在电商平台提供的仓库中。为了提高供应链的效率和准确性,电商平台需要科学地管理货物并做出智能决策。通过使用大数据和智能技术,可以有效降低库存成本,并确保按时交付商品。在供应链优化问题中,我们需要解决以下几个方面的内容:
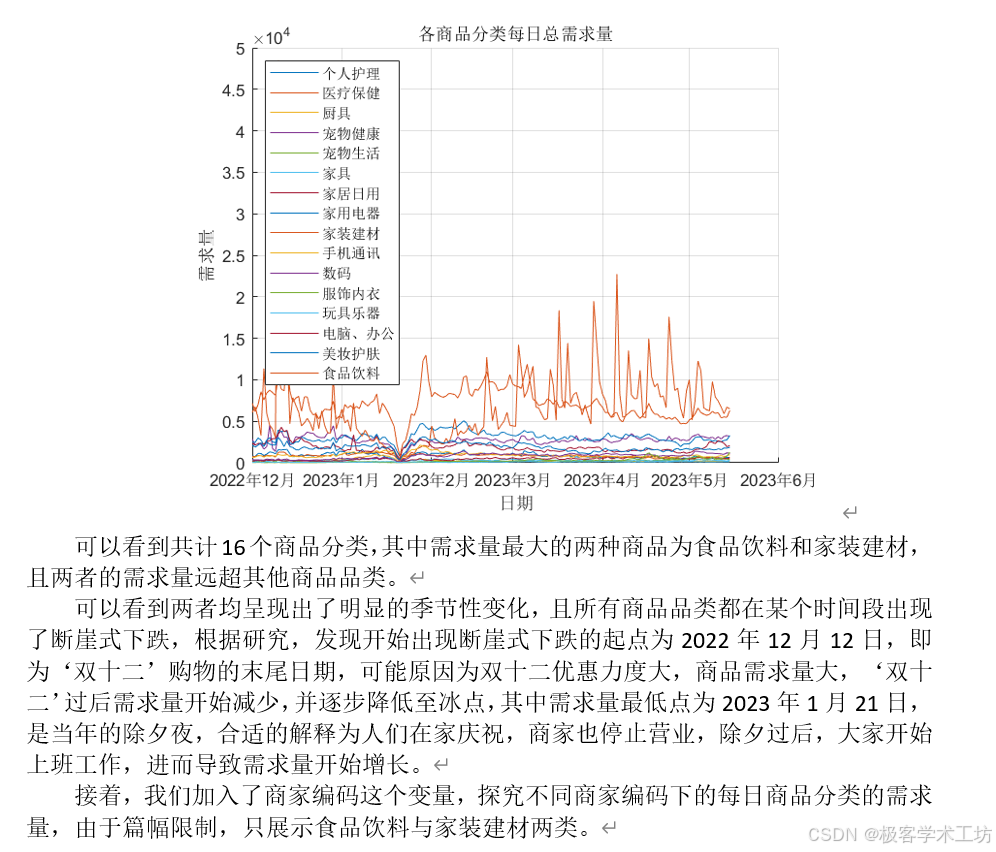
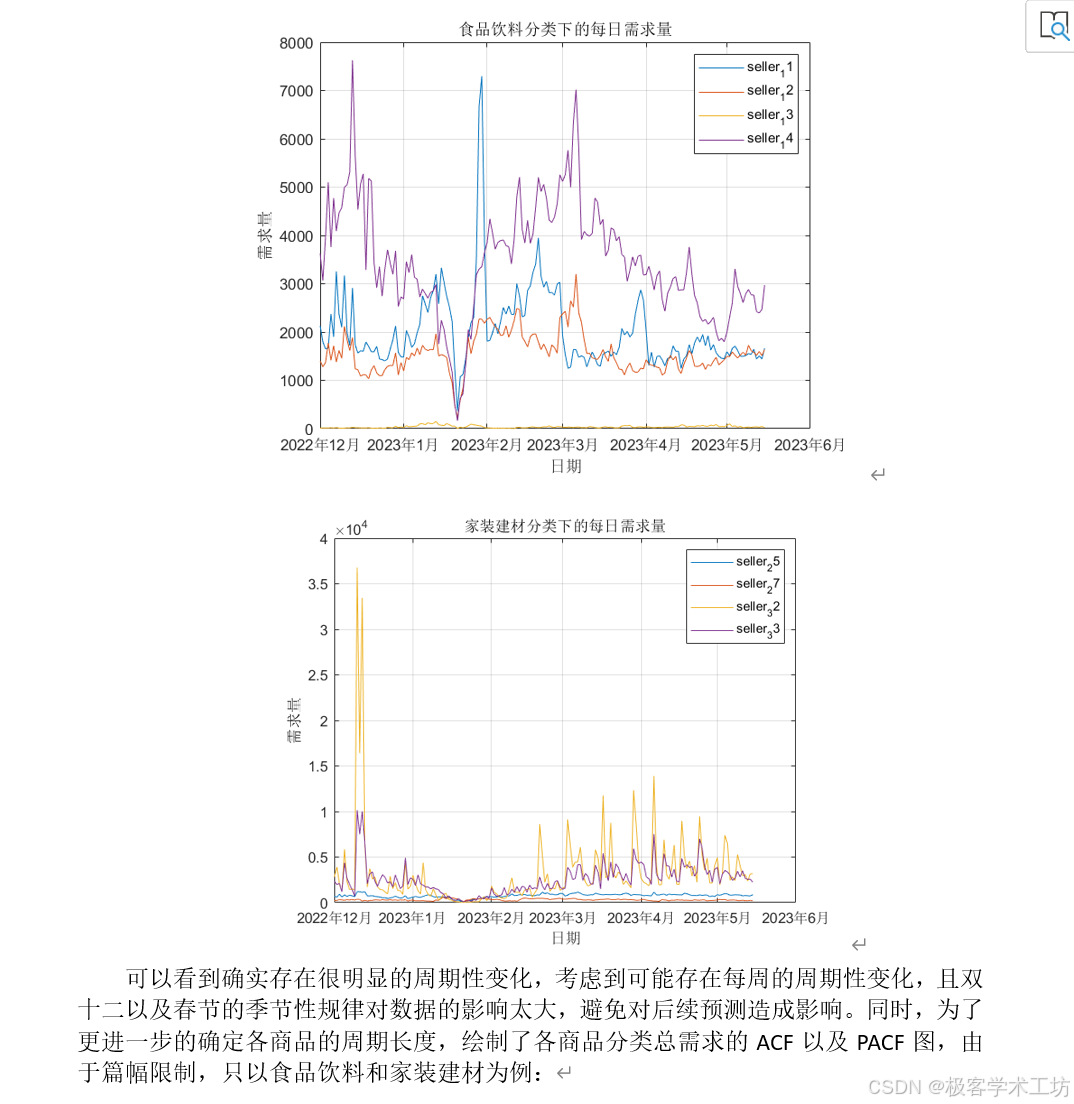
问题一:根据附件1-4中的数据,我们需要预测每个商家在每个仓库的商品在2023-05-16至2023-05-30期间的需求量。我们可以使用这些预测结果填写在结果表1中,并上传至竞赛平台。同时,我们还需要评估模型的预测性能。在数据分析和建模过程中,我们可以将商家、仓库和商品组合成时间序列,并根据它们的需求特征将其进行分类。通过分类,我们可以找到各类别之间需求特征最为相似的序列。
问题二:对于新出现的商家+仓库+商品维度(附件5),我们需要参考历史附件1中的数据,找到相似的序列,并完成对这些维度在2023-05-16至2023-05-30期间的需求量的预测。我们将这些预测结果填写在结果表2中,并上传至竞赛平台。通过使用历史数据,我们可以寻找与新维度最相似的序列来进行预测,这可能是由于新上市商品或更改商品存放仓库引起的。通过参考相似序列,我们可以通过历史数据中的趋势和模式来预测新维度的需求量。
问题三:每年6月会有大型促销活动,这给需求量的准确预测和按时交付带来了挑战。附件6提供了去年双十一期间商家+仓库+商品维度的需求量数据,我们可以参考这些数据来预测2023-06-01至2023-06-20期间的需求量。我们将这些预测结果填写在结果表3中,并上传至竞赛平台。在预测过程中,我们可以利用附件6中的历史数据,考虑季节性因素和促销活动的影响,采用适当的时间序列模型进行需求量预测,如季节性ARIMA模型或季节性指数平滑模型。
对于上述问题,可以使用以下模型或算法进行求解:
问题一:预测商家在每个仓库的商品需求量。这是一个时间序列预测问题,可以考虑使用基于统计的方法,如ARIMA模型、季节性指数平滑模型等。这些模型可以根据历史数据的趋势和季节性来预测未来的需求量。另外,可以使用机器学习算法,如回归模型、神经网络等,通过训练历史数据来预测未来需求量。在数据分析和建模过程中,可以将商家、仓库和商品组合成时间序列,并进行分类以找到相似的序列。可以使用聚类算法,如K-means算法,将序列划分为不同的类别,使得同一类别内的序列在需求特征上最为相似。
问题二:预测新出现的商家、仓库、商品维度的需求量。可以根据历史附件1中的数据,找到与新维度最相似的序列,并进行需求量预测。一种方法是计算新维度与历史序列之间的相似性度量,如欧氏距离、相关系数等,然后选择最相似的序列进行预测。另外,可以使用时间序列相似性匹配算法,如DTW(动态时间规整)算法,来寻找相似序列并进行预测。
问题三:预测大型促销期间的需求量。可以参考附件6中去年双十一期间的需求量数据,并考虑季节性因素和促销活动的影响。可以使用季节性ARIMA模型或季节性指数平滑模型来建模和预测需求量。这些模型可以捕捉到季节性变化和促销活动对需求量的影响,并进行准确预测。
综上所述,对于问题一、问题二和问题三,可以采用时间序列预测模型(如ARIMA、指数平滑等)、聚类算法(如K-means)和时间序列相似性匹配算法(如DTW),结合历史数据和特定的需求特征,来进行供应链的优化和需求量的预测。

更多推荐


 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)