
Pandas进行数据预处理(清洗数据)②
Pandas进行数据预处理(清洗数据)
·
数据清洗与异常值处理代码解析
数据清洗与异常值处理代码解析
本文将详细解析一段用于数据清洗和异常值处理的Python代码,该代码使用了pandas、numpy、scipy和matplotlib等库,实现了数据去重、相似度计算、缺失值处理、插值以及异常值识别等功能。
1. 导入必要的库
import pandas as pd
import numpy as np
from scipy.interpolate import interp1d, lagrange
import matplotlib.pyplot as plt
import os
代码解析:
pandas:用于数据处理和分析,提供了高效的数据结构如DataFrame和Series。numpy:用于数值计算,提供了多维数组对象和各种数学函数。scipy.interpolate:提供了插值函数,如interp1d和lagrange。matplotlib.pyplot:用于数据可视化,绘制图表。os:用于与操作系统进行交互,处理文件和目录路径。
2. 构建文件路径
准备工作

2.
# 构建文件路径
# 构建文件路径
data_dir = 'data'
tmp_dir = 'tmp'
3. 读取数据
代码 4 - 7
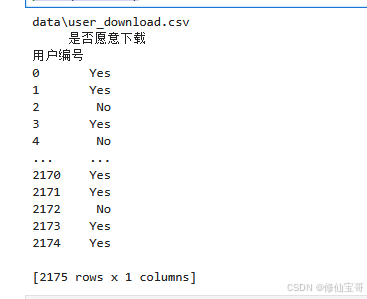
download_path = os.path.join(data_dir, 'user_download.csv')
print(download_path)
# 使用 GB2312 编码读取文件
download = pd.read_csv(download_path, index_col=0, encoding='gb2312')
print(download)
代码解析:
pd.read_csv():用于读取CSV文件。index_col=0:指定第一列为索引列。encoding='gb2312':指定文件编码为gb2312。
结果
4. 数据去重
方法一:自定义去重函数
# 定义去重函数
def del_rep(list1):
list2 = []
for i in list1:
if i not in list2:
list2.append(i)
return list2
# 去重
# 将下载意愿从数据框中提取出来
download_list = list(download['是否愿意下载'])
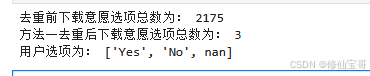
print('去重前下载意愿选项总数为:', len(download_list))
download_rep = del_rep(download_list) # 使用自定义的去重函数去重
print('方法一去重后下载意愿选项总数为:', len(download_rep))
print('用户选项为:', download_rep)
代码解析:
del_rep():自定义的去重函数,通过遍历列表,将不在新列表中的元素添加到新列表中。download['是否愿意下载']:从DataFrame中提取是否愿意下载列。list():将Series对象转换为列表。
结果
方法二:使用set去重
# 代码 4 - 8
# 方法二
print('去重前下载意愿选项总数为:', len(download_list))
download_set = set(download_list) # 利用set的特性去重
print('方法二去重后下载意愿选项总数为:', len(download_set))
print('用户选项为:', download_set)
代码解析:
set():将列表转换为集合,集合的元素具有唯一性,从而实现去重。
结果

检测与处理重复值


方法三:使用drop_duplicates方法
# 代码 4 - 9
# 对下载意愿去重
download = pd.read_csv(download_path, encoding='gb2312')
download_select = download['是否愿意下载'].drop_duplicates()
print('drop_duplicates方法去重之后下载意愿选项总数为:', len(download_select))
代码解析:
drop_duplicates():pandas的Series对象的方法,用于去除重复值。
结果

对用户总信息表去重
# 代码 4 - 10
all_info = pd.read_csv('./data/user_all_info.csv',encoding="gbk")
print('去重之前用户的形状为:', all_info.shape)
shape_det = all_info.drop_duplicates(subset=['用户编号', '编号']).shape
print('依照用户编号,编号去重之后用户总信息表大小为:', shape_det)
代码解析:
drop_duplicates(subset=['用户编号', '编号']):根据用户编号和编号列去除重复行。
结果

5. 相似度计算
计算年龄和每月支出的相似度
# 代码 4 - 11
# 求取年龄和每月支出的相似度
corr_det = all_info[['年龄', '每月支出']].corr(method='kendall')
print('年龄和每月支出的相似度矩阵为:\n', corr_det)
代码解析:
corr(method='kendall'):计算相关系数矩阵,method='kendall'表示使用Kendall秩相关系数。
结果

计算居住类型、年龄和每月支出的相似度
# 代码 4 - 12
import pandas as pd
all_info = pd.read_csv('./data/user_all_info.csv',encoding="gbk")
# 将“居住类型”列转换为数值类型(标签编码,假设只有城市和农村)
all_info['居住类型'] = all_info['居住类型'].map({'城市': 1, '农村': 0})
# 计算 Pearson 相关系数
corr_det1 = all_info[['居住类型', '年龄', '每月支出']].corr(method='pearson')
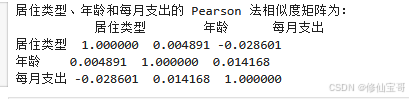
print('居住类型、年龄和每月支出的 Pearson 法相似度矩阵为:\n', corr_det1)
代码解析:
corr(method='pearson'):计算相关系数矩阵,method='pearson'表示使用皮尔逊相关系数。
结果
6. 特征相等矩阵计算与去重
定义求取特征是否完全相同的矩阵的函数

# 代码 4 - 13
# 定义求取特征是否完全相同的矩阵的函数
def feature_equals(df):
# 使用DataFrame的列名初始化一个全为False的矩阵,确保结构正确
df_equals = pd.DataFrame(False, index=df.columns, columns=df.columns)
for i in df.columns:
for j in df.columns:
# 比较列i和列j是否完全相等(数据和索引均一致)
df_equals.loc[i, j] = df[i].equals(df[j])
return df_equals
# 应用上述函数
app_desire = feature_equals(all_info)
print('app_desire的特征相等矩阵的前7行7列为:\n', app_desire.iloc[:7, :7])
代码解析:
feature_equals():自定义函数,用于计算特征相等矩阵。equals():用于比较两个Series对象是否完全相同。
结果

去除重复列
# 代码 4 - 14
# 遍历所有数据
len_feature = app_desire.shape[0]
dup_col = []
for m in range(len_feature):
for n in range(m + 1, len_feature):
if app_desire.iloc[m, n] & (app_desire.columns[n] not in dup_col):
dup_col.append(app_desire.columns[n])
# 进行去重操作
print('需要删除的列为:', dup_col)
all_info.drop(dup_col, axis=1, inplace=True)
print('删除多余列后all_info的特征数目为:', all_info.shape[1])
代码解析:
- 通过遍历特征相等矩阵,找出重复的列名。
drop(dup_col, axis=1, inplace=True):删除指定的列,axis=1表示列方向,inplace=True表示在原DataFrame上进行修改。
结果
7. 缺失值处理
查看缺失值和非缺失值数量
# 代码 4 - 15
print('all_info每个特征缺失的数目为:\n', all_info.isnull().sum())
print('all_info每个特征非缺失的数目为:\n', all_info.notnull().sum())
代码解析:
isnull().sum():计算每个特征的缺失值数量。notnull().sum():计算每个特征的非缺失值数量。
结果
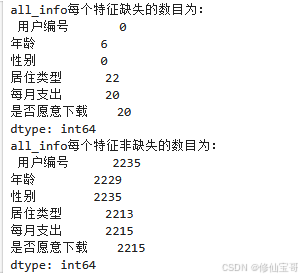
删除包含缺失值的行

# 代码 4 - 16
print('去除缺失的行前all_info的形状为:', all_info.shape)
all_info1 = all_info.dropna(axis=0, how='any')
print('去除缺失的行后all_info的形状为:', all_info1.shape)
all_info1_path = os.path.join(tmp_dir, 'all_info_notnull.csv')
all_info1.to_csv(all_info1_path, index=False)

代码解析:
dropna(axis=0, how='any'):删除包含缺失值的行,axis=0表示行方向,how='any'表示只要有一个缺失值就删除该行。to_csv():将DataFrame保存为CSV文件,index=False表示不保存索引列。
结果
用均值填充缺失值

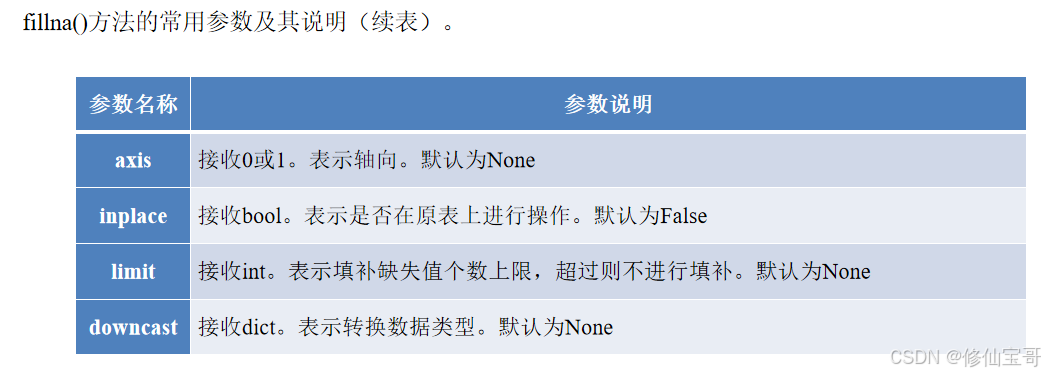
# 代码 4 - 17
# 求每月支出平均值
mean_num = all_info['每月支出'].mean()
# 缺失值替换为均值
all_info['每月支出'] = all_info['每月支出'].fillna(mean_num)
print('每月支出特征缺失的数目为:\n', all_info['每月支出'].isnull().sum())
代码解析:
mean():计算均值。fillna(mean_num):用均值填充缺失值。
结果

8. 插值方法

线性插值
# 代码 4 - 18
# 线性插值
# 创建自变量x
x = np.array([1, 2, 3, 4, 5, 8, 9, 10])
# 创建因变量y1
y1 = np.array([2, 8, 18, 32, 50, 128, 162, 200])
# 创建因变量y2
y2 = np.array([3, 5, 7, 9, 11, 17, 19, 21])
# 线性插值拟合x、y1
linear_ins_value1 = interp1d(x, y1, kind='linear')
# 线性插值拟合x、y2
linear_ins_value2 = interp1d(x, y2, kind='linear')
print('当x为6、7时,使用线性插值y1为:', linear_ins_value1([6, 7]))
print('当x为6、7时,使用线性插值y2为:', linear_ins_value2([6, 7]))
代码解析:
interp1d(x, y, kind='linear'):创建线性插值函数,kind='linear'表示线性插值。
结果



拉格朗日插值
# 拉格朗日插值
large_ins_value1 = lagrange(x, y1) # 拉格朗日插值拟合x、y1
large_ins_value2 = lagrange(x, y2) # 拉格朗日插值拟合x、y2
print('当x为6,7时,使用拉格朗日插值y1为:', large_ins_value1([6, 7]))
print('当x为6,7时,使用拉格朗日插值y2为:', large_ins_value2([6, 7]))
代码解析:
lagrange(x, y):创建拉格朗日插值多项式。
结果

样条插值
# 样条插值
# 样条插值拟合x、y1
y1_new = np.linspace(x.min(), x.max(), 10)
f = interp1d(x, y1, kind='cubic') # 编辑插值函数格式
spline_ins_value1 = f(y1_new) # 通过相应的插值函数求得新的函数点
# 样条插值拟合x、y2
y2_new = np.linspace(x.min(), x.max(), 10)
f = interp1d(x, y2, kind='cubic') # 编辑插值函数格式
spline_ins_value2 = f(y2_new) # 通过相应的插值函数求得新的函数点
print('使用样条插值y1为:', spline_ins_value1)
print('使用样条插值y2为:', spline_ins_value2)
代码解析:
interp1d(x, y, kind='cubic'):创建三次样条插值函数。np.linspace():生成指定区间内的等间距数组。
结果

9. 异常值识别
3σ原则识别异常值
# 代码 4 - 19
all_info = pd.read_csv(all_info1_path)
# 定义3σ原则来识别异常值函数
def out_range(ser1):
std = ser1.std()
if std == 0:
return pd.Series([])
bool_ind = (ser1.mean() - 3 * std > ser1) | (ser1.mean() + 3 * std < ser1)
index = np.arange(ser1.shape[0])[bool_ind]
outrange = ser1.iloc[index]
return outrange
outlier = out_range(all_info['年龄'])
print('使用3σ原则判定异常值个数为:', outlier.shape[0])
print('异常值的最大值为:', outlier.max())
print('异常值的最小值为:', outlier.min())
代码解析:
out_range():自定义函数,使用3σ原则识别异常值。std():计算标准差。mean():计算均值。
结果

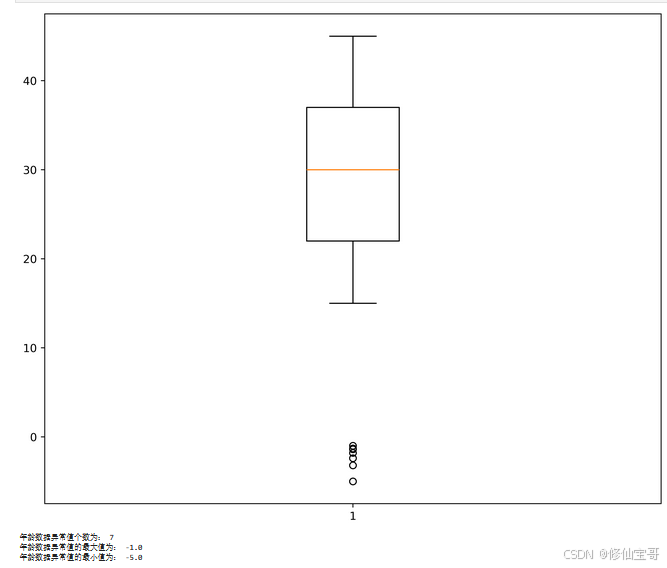
箱线图识别异常值

# 代码 4 - 20
plt.figure(figsize=(10, 8), dpi=1080)
p = plt.boxplot(list(all_info['年龄'].values)) # 画出箱线图
outlier1 = p['fliers'][0].get_ydata() # fliers为异常值的标签
img_path = os.path.join(tmp_dir, '用户年龄异常数据识别.jpg')
plt.savefig(img_path)
plt.show()
print('年龄数据异常值个数为:', len(outlier1))
print('年龄数据异常值的最大值为:', max(outlier1))
print('年龄数据异常值的最小值为:', min(outlier1))
代码解析:
plt.boxplot():绘制箱线图。p['fliers'][0].get_ydata():获取箱线图中的异常值。plt.savefig():保存图片。plt.show():显示图片。
结果
总结
通过本文的学习,读者可以掌握以下知识和技能:
- 使用
pandas进行数据读取、去重、缺失值处理和相关系数计算。 - 自定义函数实现数据去重和异常值识别。
- 使用
scipy进行插值计算,包括线性插值、拉格朗日插值和样条插值。 - 使用
matplotlib绘制箱线图识别异常值。
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)