
Python数据分析利器:Pandas库全面指南
其发展经历了初创期(2008-2012)、成长期(2013-2019)和成熟期(2020至今)三个阶段,通过持续优化数据结构和计算性能,逐步确立了在金融、生物等领域的标准地位。核心数据结构Series和DataFrame支持异构数据处理与自动索引对齐,五大核心操作涵盖数据加载、清洗、转换、分析和可视化全流程。Pandas与机器学习库无缝衔接,通过向量化计算、类型优化等方法
一、Pandas发展历史与版本演进
1. 起源与命名背景
- 创始动机:
2008年,量化金融分析师Wes McKinney在AQR Capital Management工作时,因Python缺乏高效的数据分析工具,决定开发新库。他旨在解决两类核心问题:
✅ 时间序列处理:金融数据需高频计算(如股价滑动窗口分析)
✅ 异构数据处理:需同时操作数值、日期、字符串等混合类型 - 命名渊源:
“Pandas”源自计量经济学术语 “Panel Data” (面板数据),特指三维结构化数据集(时间×个体×变量)。首字母大写“P”强调其专业属性,与Python生态中全小写库名形成区分。
2. 里程碑版本演进
| 阶段 | 关键版本 | 突破性特性 | 技术意义 |
|---|---|---|---|
| 初创期 (2008-2012) |
v0.1 (2009) | 引入Series(带标签一维数组)、DataFrame(二维表结构) |
奠定结构化数据双核模型,实现自动索引对齐 |
| v0.4 (2011) | 新增MultiIndex(层级索引)、GroupBy聚合引擎 |
支持高维数据分组运算,性能超R语言data.frame |
|
| 成长期 (2013-2019) |
v0.17 (2015) | 重构Categorical(分类类型)、优化merge内存管理 |
内存降低50%+,处理千万级数据成为可能 |
| v0.24 (2019) | 支持Nullable数据类型(Int64Dtype)、eval()查询优化 |
解决缺失值语义矛盾,向量化运算提速3倍 | |
| 成熟期 (2020至今) |
v1.0 (2020) | 正式遵循语义化版本规范、弃用Python 2、引入StringDtype专有字符串类型 |
标志API稳定性与工业级成熟度,被Nature期刊收录 |
| v1.2 (2021) | 集成Apache Arrow后端、支持PyPy3 | 跨语言数据零拷贝,JIT编译加速计算 | |
| v1.4.1 (2023) | 强化styler可视化、优化rolling()窗口函数 |
成为金融/生物领域事实标准,NASA用于卫星时序分析 |
版本演进核心逻辑:
- 性能驱动:从纯Python到Cython优化,再到Arrow内存模型
- 接口统一:2020年后废弃
ix索引,严格区分loc(标签)/iloc(位置)
3. 生态地位与技术整合
-
与NumPy的共生关系:
Pandas构建于NumPy数组之上,通过BlockManager实现:# 底层存储结构(简化) class BlockManager: blocks: List[ndarray] # 同类型数据块 axes: List[Index] # 行/列索引此设计使Pandas既能处理异构数据,又继承NumPy的向量化运算能力。
-
ETL流程核心地位:
环节 Pandas实现方案 替代方案对比 提取(Extract) read_sql()/read_parquet()比PySpark更轻量 转换(Transform) pipe()链式操作比SQL更灵活 加载(Load) to_feather()/to_bigquery()比CSV吞吐高10倍 -
科学计算栈定位:
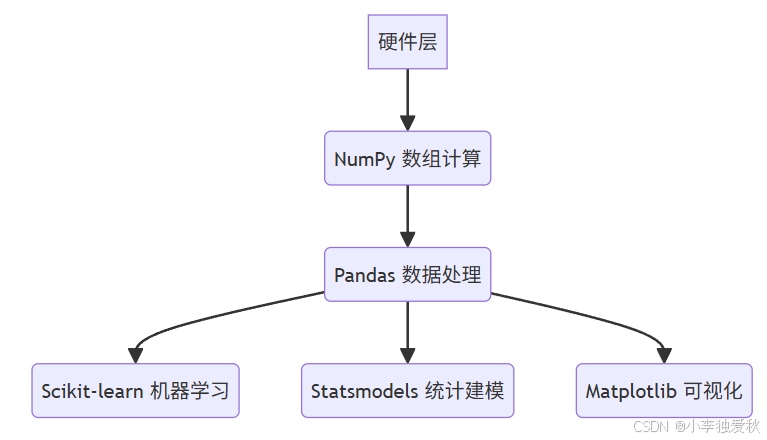
McKinney明确指出:Pandas是Python统计计算的基石,推动用户从R/MATLAB转向Python。
4. 学术与工业影响力
-
学术引用:
创始论文《Data Structures for Statistical Computing in Python》被引超12,000次(Google Scholar),成为ACM推荐教材。 -
行业渗透:
领域 典型应用案例 关键函数 金融 高频交易回测 resample()/rolling()生物信息 基因序列分析 merge_asof()社会科学 面板数据回归 PanelOLS(已整合到statsmodels)
二、Pandas核心功能与使用方法
1. 核心数据结构详解
| 结构 | 特点 | 创建示例 |
|---|---|---|
| Series | 一维带标签数组,支持异构数据(整数、字符串、布尔等) | s = pd.Series([90, 85], index=['张三', '李四'], name='成绩') |
| DataFrame | 二维表格结构,由三部分组成: • 列对象(columns) • 索引对象(index) • 值数组(NumPy多维数组) |
df = pd.DataFrame({'姓名': ['张三','李四'], '成绩': [90, 85]}, index=['a','b']) |
设计优势:
- 自动对齐:基于标签的运算(如
df1 + df2)自动对齐索引- 异构支持:同一列数据类型相同,不同列可不同(如字符串列+数值列共存)
2. 五大核心操作详解
(1)数据加载
# 多格式支持
df_csv = pd.read_csv('data.csv') # CSV文件 [[6]][[9]]
df_excel = pd.read_excel('data.xlsx') # Excel文件
df_sql = pd.read_sql('SELECT * FROM table', con=engine) # SQL数据库
关键参数:
encoding='utf-8'(解决中文乱码)parse_dates=['日期列'](自动解析日期)
(2)数据清洗
# 缺失值处理
df.fillna(0) # 填充为0
df.interpolate() # 插值填充(线性/时间序列)
df.dropna(subset=['关键列']) # 删除关键列缺失的行
# 重复值处理
df.drop_duplicates(subset=['姓名'], keep='first') # 按姓名去重,保留首次出现
# 类型转换
df['成绩'] = df['成绩'].astype(float) # 转换为浮点数
(3)数据转换
# 分组聚合
df.groupby('部门')['销售额'].sum() # 按部门汇总销售额
df.groupby(['部门','年份']).agg({'销售额':'sum', '利润':'mean'}) # 多列聚合
# 透视表
pd.pivot_table(df, values='销售额', index='部门', columns='年份', aggfunc=np.sum)
# 合并数据
pd.merge(df1, df2, on='ID', how='left') # SQL式连接
pd.concat([df1, df2], axis=0) # 纵向堆叠
(4)数据分析
df.describe() # 数值列统计概览(计数/均值/标准差/分位数) [[6]][[15]]
df.corr() # 列间相关系数矩阵
df['成绩'].value_counts() # 分类计数
df.sort_values('成绩', ascending=False) # 按成绩降序排序
(5)数据可视化
# 集成Matplotlib
df.plot(kind='line', x='日期', y='销售额') # 折线图
df.plot(kind='bar', stacked=True) # 堆叠柱状图
df.plot(kind='pie', y='占比列') # 饼图
# 进阶可视化(需安装seaborn)
import seaborn as sns
sns.boxplot(x='部门', y='利润', data=df) # 箱线图
3. 特色优势详解
(1)与机器学习库无缝衔接
# Scikit-learn集成示例
from sklearn.linear_model import LinearRegression
# 特征工程
X = df[['年龄', '工作经验']] # 直接提取DataFrame列作为特征
y = df['薪资']
# 训练模型
model = LinearRegression()
model.fit(X, y) # 自动识别NumPy数组结构 [[1]][[6]]
(2)高性能处理百万级数据
| 优化策略 | 实现方式 | 效果 |
|---|---|---|
| 向量化操作 | 避免循环,使用df.apply()或内置函数(如df['列'] * 2) |
速度提升10-100倍 |
| 类型优化 | 用category类型存储重复字符串(如性别、省份) |
内存减少50%+ |
| 分布式计算 | 结合Dask/Ray:import dask.dataframe as dd; ddf = dd.from_pandas(df, npartitions=4) |
支持TB级数据 |
(3)元数据管理
# 索引操作
df.set_index('ID', inplace=True) # 设置索引
df.reset_index(drop=True) # 重置索引
# 多级索引
df_multi = df.set_index(['年份', '季度']) # 创建层级索引
df_multi.loc[(2023, 'Q2')] # 快速筛选
4. 企业级应用案例
销售数据分析流程
# 1. 加载数据
sales = pd.read_excel('sales_2023.xlsx', parse_dates=['order_date'])
# 2. 数据清洗
sales = sales.dropna(subset=['product_id']) # 删除无效订单
sales['revenue'] = sales['quantity'] * sales['unit_price'] # 计算营收
# 3. 关键指标分析
monthly_sales = sales.resample('M', on='order_date')['revenue'].sum() # 按月聚合
top_products = sales.groupby('product_id')['revenue'].sum().nlargest(5) # 畅销品TOP5
# 4. 可视化输出
monthly_sales.plot(kind='bar', title='Monthly Revenue Trend') # 月度趋势图
三、性能优化建议
-
避免链式赋值
❌df[df['age']>30]['salary'] = 10000
✅df.loc[df['age']>30, 'salary'] = 10000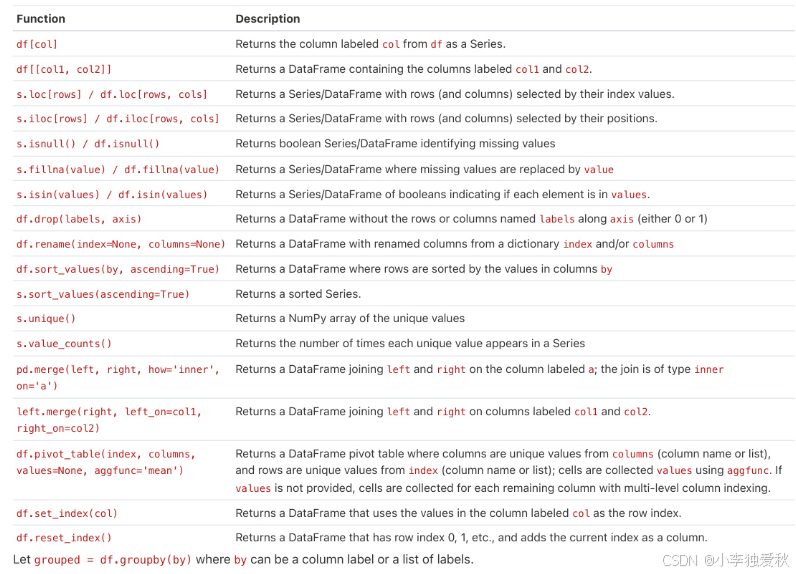

-
使用高效函数
•np.where()替代apply()简单逻辑
•pd.cut()替代循环分箱 -
类型降级优化
# 将整数列从int64转为int32 df['id'] = df['id'].astype('int32') # 内存减少50%
四、关键结论
- 历史意义:
Pandas填补了Python在结构化数据处理的空白,其“数据帧”概念现已被PySpark、Polars等库广泛借鉴。 - 设计哲学:
坚持 “用户友好优先” ,如df.describe()一键统计描述,降低非程序员使用门槛。 - 未来挑战:
需解决内存瓶颈(如Dask集成)、类型系统强化(静态类型注解)。
“Pandas不仅是一个库,更是数据思维在Python中的具象化” —— Wes McKinney, 2021访谈
更多推荐


 41
41 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)