
Python-Pandas数据处理实战项目笔记
有时数据格式并不标准,需要使用自定义函数对原始数据进行解析。格式函数名特点CSVto_csv()易读,通用Excelto_excel()支持多表JSONto_json()适合Web传输Parquet压缩高效,适合大数据HDF5to_hdf()支持复杂结构本章系统讲解了缺失值识别与处理策略,以及数据清洗的其他常见操作,包括:使用isna()和可视化工具识别缺失值;采用删除、填充、插值等方式处理缺失;

简介:Pandas是Python中用于数据科学的核心库之一,提供高效的数据操作接口,简化了数据清洗、转换和分析流程。本项目包含两个真实应用场景:“能源市场分析-西班牙”和“Spotify个人流分析”,通过Jupyter Notebook形式展示Pandas在实际问题中的强大功能。内容涵盖DataFrame基础、数据导入、预处理、筛选、分组聚合、透视重塑、时间序列分析、合并连接、可视化等关键技能,帮助学习者掌握完整数据处理流程,提升数据分析实战能力。 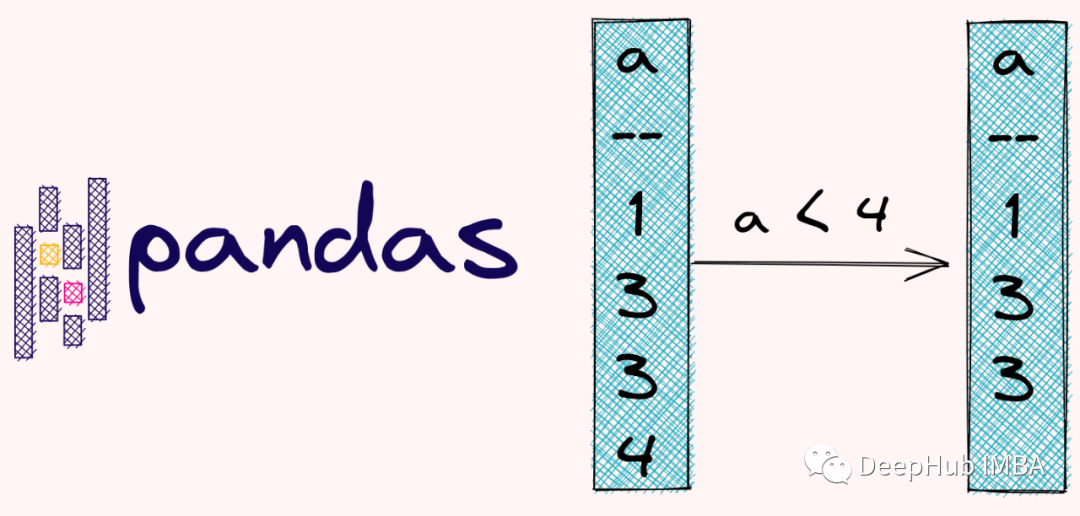
1. Pandas核心数据结构DataFrame
1.1 DataFrame的基本特性
Pandas 的 DataFrame 是一个二维的、大小可变的、具有行标签和列标签的表格型数据结构,类似于 Excel 表格或 SQL 中的数据表。它支持多种数据类型(如整数、浮点数、字符串、布尔值等),非常适合进行数据分析和处理。
import pandas as pd
# 示例:创建一个简单的DataFrame
data = {
'姓名': ['张三', '李四', '王五'],
'年龄': [25, 30, 28],
'工资': [8000, 9500, 7800]
}
df = pd.DataFrame(data)
print(df)
执行结果:
姓名 年龄 工资
0 张三 25 8000
1 李四 30 9500
2 王五 28 7800
参数说明:
- data :字典结构,键为列名,值为对应的列数据。
- pd.DataFrame() :用于将数据转换为 DataFrame 对象。
DataFrame 的行可以通过索引访问,列可以通过列名访问,这使得数据操作非常灵活。
1.2 DataFrame与Series的关系
在 Pandas 中, Series 是一维的带标签数组,而 DataFrame 可以看作是由多个 Series 组成的字典结构,每个 Series 代表一列数据。
例如,提取上面 DataFrame 中的“年龄”列:
age_series = df['年龄']
print(age_series)
执行结果:
0 25
1 30
2 28
Name: 年龄, dtype: int64
该输出就是一个 Series ,它保留了原始 DataFrame 的行索引信息。
因此,我们可以认为:
- DataFrame 是多个 Series 的集合。
- 每个 Series 对应一个字段(列)。
- DataFrame 支持对 Series 进行统一操作,如筛选、排序、聚合等。
2. 多种格式数据导入与加载方法
在数据科学和数据分析领域,数据导入是所有工作的起点。Pandas 提供了多种方式从不同格式的文件和数据源中加载数据到 DataFrame 中。掌握这些方法不仅能提高数据处理的效率,还能帮助开发者在面对不同类型的数据源时更加游刃有余。本章将详细介绍如何从 CSV、Excel、数据库等常见数据格式中导入数据,同时也会探讨一些高级技巧,如分块读取、列选择、行筛选以及自定义解析函数的应用。此外,我们还将介绍如何将 DataFrame 导出为不同格式,实现数据的转换与共享。
2.1 数据导入的基本方式
Pandas 支持从多种数据源中导入数据,包括但不限于 CSV 文件、Excel 表格、SQL 数据库等。掌握这些基础的导入方式是构建数据工作流的第一步。
2.1.1 从CSV文件导入数据
CSV(Comma-Separated Values)是一种常见的文本格式,广泛用于存储表格数据。Pandas 提供了 read_csv() 函数来读取 CSV 文件。
示例代码:
import pandas as pd
# 从本地文件读取CSV数据
df = pd.read_csv('data.csv')
# 显示前5行数据
print(df.head())
代码逻辑分析:
pd.read_csv('data.csv'):读取当前目录下的data.csv文件,并返回一个 DataFrame 对象。df.head():默认显示前5行数据,便于快速查看数据内容。
参数说明:
| 参数名 | 描述 |
|---|---|
filepath_or_buffer |
文件路径或URL |
sep |
分隔符,默认为逗号( , ) |
header |
指定第几行作为列名,默认为0 |
index_col |
指定哪一列作为行索引 |
dtype |
指定列的数据类型 |
进阶操作:
# 指定列名和数据类型
df = pd.read_csv('data.csv', names=['col1', 'col2'], dtype={'col1': str, 'col2': float})
注意事项:
- 如果 CSV 文件较大,建议使用
chunksize参数进行分块读取(见 2.2.2 节)。 - 编码问题可能导致读取失败,可以尝试使用
encoding='utf-8'或latin1等参数。
2.1.2 从Excel表格读取数据
Excel 是企业中广泛使用的数据管理工具,Pandas 提供了 read_excel() 函数来读取 .xls 或 .xlsx 文件。
示例代码:
# 从Excel文件读取数据
df = pd.read_excel('data.xlsx', sheet_name='Sheet1')
print(df.head())
代码逻辑分析:
sheet_name='Sheet1':指定读取的工作表名称,默认为第一个工作表。pd.read_excel()返回的仍然是一个 DataFrame。
参数说明:
| 参数名 | 描述 |
|---|---|
sheet_name |
工作表名称或索引 |
header |
指定哪一行作为列名 |
index_col |
指定索引列 |
dtype |
列数据类型映射 |
进阶操作:
# 读取多个工作表并合并
dfs = pd.read_excel('data.xlsx', sheet_name=['Sheet1', 'Sheet2'])
df_combined = pd.concat(dfs.values(), ignore_index=True)
注意事项:
- 需要安装
openpyxl或xlrd等支持 Excel 的库。 - Excel 文件结构复杂时,建议先查看数据结构再导入。
2.1.3 从数据库读取数据
Pandas 支持与 SQL 数据库进行交互,常用的方式是通过 SQLAlchemy 或 sqlite3 等库建立连接,然后使用 read_sql() 函数读取数据。
示例代码(SQLite):
import sqlite3
import pandas as pd
# 连接到SQLite数据库
conn = sqlite3.connect('example.db')
# 从数据库中读取数据
query = "SELECT * FROM my_table"
df = pd.read_sql(query, conn)
print(df.head())
代码逻辑分析:
sqlite3.connect():建立数据库连接。pd.read_sql():执行 SQL 查询并返回 DataFrame。
示例代码(使用 SQLAlchemy):
from sqlalchemy import create_engine
import pandas as pd
# 创建数据库连接引擎
engine = create_engine('mysql+pymysql://user:password@localhost/dbname')
# 读取数据
query = "SELECT * FROM my_table"
df = pd.read_sql(query, engine)
print(df.head())
参数说明:
| 参数名 | 描述 |
|---|---|
sql |
SQL 查询语句或表名 |
con |
数据库连接对象 |
index_col |
指定作为索引的列 |
注意事项:
- 需要安装数据库驱动(如
pymysql,psycopg2等)。 - 查询语句应尽量优化,避免一次性加载过多数据。
2.2 高级数据加载技巧
除了基本的导入方式,Pandas 还提供了一些高级功能来处理大型数据集和复杂的数据结构。
2.2.1 指定列和行的加载
在处理大型数据集时,我们往往不需要加载全部列或行,只选择感兴趣的字段可以提高效率。
示例代码:
# 只加载特定列
df = pd.read_csv('data.csv', usecols=['name', 'age'])
# 加载前1000行
df = pd.read_csv('data.csv', nrows=1000)
参数说明:
| 参数名 | 描述 |
|---|---|
usecols |
指定要读取的列名或列索引列表 |
nrows |
指定要读取的最大行数 |
进阶操作:
# 使用函数筛选列
df = pd.read_csv('data.csv', usecols=lambda col: col not in ['id', 'timestamp'])
2.2.2 大文件分块读取
当处理非常大的数据文件时,一次性加载可能会导致内存溢出。Pandas 支持使用 chunksize 参数将文件分块读取。
示例代码:
# 分块读取CSV文件
for chunk in pd.read_csv('big_data.csv', chunksize=10000):
process(chunk) # 假设process()是处理数据的函数
参数说明:
| 参数名 | 描述 |
|---|---|
chunksize |
每块的行数,返回一个可迭代的 TextFileReader 对象 |
代码逻辑分析:
pd.read_csv(..., chunksize=10000)返回的是一个迭代器。- 每次迭代返回一个包含 10000 行的 DataFrame。
- 可用于逐块处理、写入数据库或进行内存优化。
性能优化建议:
- 分块读取结合
groupby或aggregation可实现大规模数据统计。 - 结合
Dask或Vaex等库可实现更高效的大数据处理。
2.2.3 自定义数据解析函数
有时数据格式并不标准,需要使用自定义函数对原始数据进行解析。
示例代码:
def custom_parser(value):
# 自定义解析逻辑,例如去除空格、转换格式等
return value.strip().lower()
# 使用自定义解析函数
df = pd.read_csv('data.csv', converters={'name': custom_parser})
代码逻辑分析:
converters参数接受一个字典,键为列名,值为对应的解析函数。custom_parser函数将在读取该列时被调用。
进阶操作:
# 多列解析
def parse_date(value):
return pd.to_datetime(value)
df = pd.read_csv('data.csv', converters={
'name': lambda x: x.upper(),
'date': parse_date
})
参数说明:
| 参数名 | 描述 |
|---|---|
converters |
字典类型,指定列的自定义解析函数 |
使用场景:
- 数据清洗预处理
- 特殊编码或格式转换
- 异常值处理前置处理
2.3 数据导出与格式转换
完成数据处理后,常常需要将结果导出为不同的格式,以便于分享、存储或用于其他系统。
2.3.1 DataFrame导出为CSV和Excel
Pandas 提供了简洁的方法将 DataFrame 导出为 CSV 或 Excel 文件。
示例代码(导出为CSV):
df.to_csv('output.csv', index=False)
参数说明:
| 参数名 | 描述 |
|---|---|
path_or_buf |
文件路径 |
index |
是否导出索引,默认为 True |
sep |
分隔符,默认为逗号 |
示例代码(导出为Excel):
df.to_excel('output.xlsx', sheet_name='Sheet1', index=False)
参数说明:
| 参数名 | 描述 |
|---|---|
excel_writer |
文件路径或 ExcelWriter 对象 |
sheet_name |
工作表名称 |
index |
是否导出索引 |
进阶操作:
# 导出多个DataFrame到不同工作表
with pd.ExcelWriter('output.xlsx') as writer:
df1.to_excel(writer, sheet_name='Sheet1')
df2.to_excel(writer, sheet_name='Sheet2')
2.3.2 数据格式的转换与保存
除了文件格式的转换,数据本身的类型也可以进行转换,以便后续处理。
示例代码(类型转换):
# 将列转换为类别类型以节省内存
df['category'] = df['category'].astype('category')
# 将列转换为日期类型
df['date'] = pd.to_datetime(df['date'])
示例代码(保存为HDF5):
# 导出为HDF5格式(适合大数据存储)
df.to_hdf('data.h5', key='df', mode='w')
支持的导出格式总结:
| 格式 | 函数名 | 特点 |
|---|---|---|
| CSV | to_csv() |
易读,通用 |
| Excel | to_excel() |
支持多表 |
| JSON | to_json() |
适合Web传输 |
| Parquet | to_parquet() |
压缩高效,适合大数据 |
| HDF5 | to_hdf() |
支持复杂结构 |
推荐策略:
- 小数据量 :CSV、Excel
- 大数据量 :Parquet、HDF5
- 跨平台交互 :JSON、CSV
- 嵌套结构 :HDF5、Feather
本章小结(非正式)
本章详细介绍了 Pandas 中从不同格式数据源导入数据的方法,包括 CSV、Excel 和数据库的读取方式,以及高级技巧如列选择、分块读取、自定义解析函数等。同时,我们也探讨了如何将处理后的数据导出为各种格式,并进行了数据类型转换的示例说明。掌握这些技能对于构建高效、灵活的数据处理流程至关重要。下一章将深入探讨数据清洗与缺失值处理技术,帮助我们更好地准备数据以供分析。
3. 数据清洗与缺失值处理技术
在数据科学项目中, 数据清洗 是构建高质量模型和获取可靠洞察的关键环节。原始数据往往包含缺失值、异常值、重复记录以及格式不一致的字段。本章将重点围绕 缺失值的识别与处理 ,以及 其他常见清洗操作 ,如重复数据删除、字符串标准化等,通过具体代码示例、操作步骤与流程图展示,帮助读者掌握系统化的数据清洗方法。
3.1 缺失值的识别与分析
缺失值是数据分析中最常见的问题之一,可能导致统计偏差、模型失效甚至系统性错误。因此,识别并理解缺失值的分布是清洗流程的第一步。
3.1.1 缺失值的表示方式
Pandas 中使用 NaN (Not a Number)表示浮点型的缺失值,而对于非浮点型数据(如字符串或整数),使用 None 表示缺失。两者在 DataFrame 中可以共存,但在某些操作中行为略有不同。
示例代码:
import pandas as pd
import numpy as np
# 创建一个包含缺失值的DataFrame
data = {
'name': ['Alice', None, 'Charlie'],
'age': [25, np.nan, 30],
'salary': [50000, 60000, None]
}
df = pd.DataFrame(data)
print(df)
输出结果:
name age salary
0 Alice 25.0 50000.0
1 None NaN 60000.0
2 Charlie 30.0 NaN
代码分析:
None被自动转换为NaN并保持 DataFrame 类型一致性。NaN是浮点数类型,因此整数列若存在缺失值会被转换为浮点类型。- 使用
isna()或isnull()方法可以检测缺失值。
print(df.isna())
name age salary
0 False False False
1 True True False
2 False False True
3.1.2 缺失值的统计分析
为了更系统地分析缺失值,我们可以统计每一列的缺失数量、比例,并可视化缺失模式。
示例代码:
# 缺失值数量统计
missing_count = df.isna().sum()
print("缺失值数量统计:\n", missing_count)
# 缺失值比例统计
missing_ratio = df.isna().mean()
print("缺失值比例统计:\n", missing_ratio)
输出结果:
缺失值数量统计:
name 1
age 1
salary 1
dtype: int64
缺失值比例统计:
name 0.333333
age 0.333333
salary 0.333333
dtype: float64
缺失值可视化(使用 missingno )
import missingno as msno
import matplotlib.pyplot as plt
msno.bar(df)
plt.title("缺失值分布柱状图")
plt.show()
流程图:缺失值识别与分析流程
graph TD
A[加载原始数据] --> B{是否存在缺失值?}
B -- 是 --> C[统计缺失值数量与比例]
B -- 否 --> D[进入下一步清洗流程]
C --> E[可视化缺失值分布]
E --> F[制定缺失值处理策略]
3.2 缺失值的处理策略
处理缺失值的方式取决于数据类型、缺失比例以及业务背景。常见的策略包括: 删除缺失记录、填充缺失值、插值法等 。
3.2.1 删除缺失值记录
当缺失值比例较低,且不影响整体分析时,可以选择删除含有缺失值的行或列。
示例代码:
# 删除含有缺失值的行
df_dropped_rows = df.dropna()
print("删除缺失行后的数据:\n", df_dropped_rows)
# 删除含有缺失值的列
df_dropped_cols = df.dropna(axis=1)
print("删除缺失列后的数据:\n", df_dropped_cols)
参数说明:
axis=0(默认)表示删除行,axis=1表示删除列。- 可使用
thresh=n参数保留至少有 n 个非空值的行/列。
逻辑分析:
- 删除缺失值简单直接,但可能导致信息丢失。
- 若某列缺失比例极高(如超过 70%),可考虑删除该列。
3.2.2 使用常量填充缺失值
填充是一种更保守的方式,尤其适用于数值型数据。
示例代码:
# 填充为0
df_fill_zero = df.fillna(0)
print("填充为0的结果:\n", df_fill_zero)
# 填充为特定值
df_fill_value = df.fillna({'age': 0, 'salary': 50000})
print("指定列填充结果:\n", df_fill_value)
参数说明:
fillna(value):用固定值填充所有缺失值。- 也可以传入字典,对不同列设置不同填充值。
逻辑分析:
- 填充为 0 或平均值是常见做法,但需注意是否引入偏差。
- 对分类变量(如
name)填充为"Unknown"更合理。
3.2.3 插值法处理缺失数据
插值法通过已有数据推测缺失值,常用于时间序列或连续变量。
示例代码:
# 创建一个带有时间索引的DataFrame
df_time = pd.DataFrame({
'value': [10, None, None, 40, 50]
}, index=pd.date_range('2023-01-01', periods=5))
# 使用线性插值
df_interpolated = df_time.interpolate()
print("线性插值结果:\n", df_interpolated)
# 使用时间插值
df_time_interpolated = df_time.interpolate(method='time')
print("时间插值结果:\n", df_time_interpolated)
参数说明:
interpolate()默认使用线性插值。method='time'适用于时间序列数据。- 支持多种插值方法:
polynomial、spline、nearest等。
逻辑分析:
- 插值适用于趋势明确的数据,如时间序列。
- 注意插值可能引入人为趋势,影响模型训练结果。
表格:不同缺失值处理策略对比
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 删除缺失值 | 简单、快速 | 信息丢失,样本减少 | 缺失比例低 |
| 固定值填充 | 保持样本完整性 | 可能引入偏差 | 分类变量或简单数值填充 |
| 插值法 | 保留趋势信息 | 复杂、可能人为增强趋势 | 时间序列、连续变量 |
3.3 数据清洗的其他操作
除了缺失值处理,数据清洗还包括 重复数据识别与删除 、 字符串清理与标准化 等常见操作。
3.3.1 重复数据的识别与删除
重复记录可能导致统计结果失真或模型过拟合。
示例代码:
# 创建一个包含重复行的DataFrame
data_dup = {
'id': [1, 2, 2, 3],
'name': ['Alice', 'Bob', 'Bob', 'Charlie']
}
df_dup = pd.DataFrame(data_dup)
# 查看重复行
print("重复行识别:\n", df_dup.duplicated())
# 删除重复行
df_no_dup = df_dup.drop_duplicates()
print("删除重复行后的数据:\n", df_no_dup)
参数说明:
duplicated()返回布尔 Series,表示某行是否为重复行。drop_duplicates()默认保留第一次出现的记录,可通过keep='last'或keep=False控制。
逻辑分析:
- 可选择基于所有列或部分列进行去重。
- 对于时间数据,保留最新记录更合理。
3.3.2 字符串数据的清理与标准化
字符串数据常常包含多余空格、大小写不统一、特殊字符等问题。
示例代码:
# 创建包含脏数据的DataFrame
df_str = pd.DataFrame({
'city': [' new york ', 'Chicago', 'los angeles ', 'NEW YORK']
})
# 去除前后空格并统一为小写
df_str['city_clean'] = df_str['city'].str.strip().str.lower()
print("标准化后的城市名:\n", df_str)
# 替换特定字符串
df_str['city_replaced'] = df_str['city_clean'].str.replace('new york', 'ny')
print("替换后的城市名:\n", df_str)
参数说明:
str.strip()去除前后空格。str.lower()转小写。str.replace()替换特定字符串。- 可结合正则表达式进行更复杂的字符串处理。
逻辑分析:
- 标准化后便于分类统计、匹配和聚类。
- 对于地址、城市名等字段尤为重要。
流程图:字符串清洗流程
graph TD
A[原始字符串数据] --> B[去除空格]
B --> C[统一大小写]
C --> D[替换特定模式]
D --> E[标准化后数据]
表格:字符串清洗常见操作
| 操作 | 方法示例 | 说明 |
|---|---|---|
| 去除空格 | str.strip() |
去除前后空格 |
| 大小写转换 | str.lower() , str.upper() |
转换为小写或大写 |
| 替换字符串 | str.replace('old', 'new') |
替换特定字符串 |
| 正则匹配提取 | str.extract(r'(\d+)') |
提取符合正则表达式的部分 |
| 分割字符串 | str.split(',') |
按指定字符分割字符串 |
总结
本章系统讲解了 缺失值识别与处理策略 ,以及 数据清洗的其他常见操作 ,包括:
- 使用
isna()和可视化工具识别缺失值; - 采用删除、填充、插值等方式处理缺失;
- 使用
drop_duplicates()消除重复记录; - 利用字符串方法清洗和标准化文本数据。
这些操作构成了数据预处理的基础流程,为后续的数据分析与建模提供了可靠的数据质量保障。在下一章中,我们将深入探讨 异常值检测与数据类型转换 ,进一步提升数据质量。
4. 异常值检测与数据类型转换
在数据预处理和分析过程中,异常值的识别与处理是不可或缺的一环。异常值可能来源于数据采集错误、系统故障或极端情况,如果不加以处理,可能会严重影响分析结果的准确性与模型的泛化能力。与此同时,数据类型的合理设置和转换也是提升数据处理效率、节省内存资源的重要手段。本章将深入探讨异常值的识别方法、处理策略以及数据类型的转换技巧,帮助读者构建完整的数据预处理能力。
4.1 异常值的识别方法
异常值(Outlier)是指与其他观测值相比显著偏离整体分布的数据点。它们可能是数据输入错误,也可能是真实世界中极端但有效的数据。识别异常值是数据清洗的重要步骤之一,有助于后续建模和分析的准确性。
4.1.1 基于统计方法的异常检测
统计方法是最基础的异常检测手段之一,常见的方法包括均值与标准差法、Z-score 和 IQR(四分位间距)法。
Z-score 方法
Z-score 是衡量一个数据点距离均值的标准差数,计算公式如下:
Z = \frac{x - \mu}{\sigma}
其中:
- $x$:数据点
- $\mu$:均值
- $\sigma$:标准差
一般认为,当 Z-score 的绝对值大于 3 时,该数据点为异常值。
代码示例:使用 Z-score 检测异常值
import pandas as pd
import numpy as np
# 构造示例数据集
np.random.seed(42)
data = np.random.normal(0, 1, 100)
data = np.append(data, [5, 6, 7]) # 添加异常值
df = pd.DataFrame(data, columns=['value'])
# 计算 Z-score
df['z_score'] = (df['value'] - df['value'].mean()) / df['value'].std()
# 标记异常值(Z-score > 3)
df['is_outlier'] = np.abs(df['z_score']) > 3
# 查看异常值
print(df[df['is_outlier']])
代码分析:
- 第1-4行:导入所需库并构造含异常值的数据集。
- 第7-8行:计算每个数据点的 Z-score。
- 第11行:设置阈值,判断是否为异常值。
- 第14行:输出异常值信息。
IQR 方法
IQR(Interquartile Range)是基于四分位数的异常检测方法。其计算步骤如下:
- 计算第一四分位数 Q1 和第三四分位数 Q3。
- 计算 IQR = Q3 - Q1。
- 定义异常值的范围:小于 Q1 - 1.5 × IQR 或大于 Q3 + 1.5 × IQR 的数据点视为异常。
# 使用 IQR 方法检测异常值
Q1 = df['value'].quantile(0.25)
Q3 = df['value'].quantile(0.75)
IQR = Q3 - Q1
# 判断是否为异常值
df['is_outlier_iqr'] = (df['value'] < (Q1 - 1.5 * IQR)) | (df['value'] > (Q3 + 1.5 * IQR))
# 输出异常值
print(df[df['is_outlier_iqr']])
代码分析:
- 第2-3行:分别计算 Q1 和 Q3。
- 第4行:计算 IQR。
- 第7行:判断是否为异常值。
- 第10行:输出异常值结果。
4.1.2 箱型图(Boxplot)分析
箱型图是一种直观的可视化工具,能够帮助我们快速识别数据中的异常值。箱型图中的箱体表示 Q1 到 Q3 的范围,上下“须”表示正常值的边界,超出“须”的点即为异常值。
import matplotlib.pyplot as plt
# 绘制箱型图
plt.figure(figsize=(8, 6))
plt.boxplot(df['value'], vert=False)
plt.title('Boxplot of Value')
plt.xlabel('Value')
plt.grid(True)
plt.show()
代码分析:
- 第3行:设置绘图尺寸。
- 第4行:使用 boxplot 绘制箱型图。
- 第5-7行:添加标题、坐标轴标签并显示网格。
- 第8行:显示图形。
图表说明:
上图中,箱型图的中线为中位数,箱体为四分位间距,两端的横线为正常范围边界,孤立的点为异常值。通过箱型图可以快速判断异常值的分布情况。
比较 Z-score 与 IQR 方法
| 方法 | 优点 | 缺点 |
|---|---|---|
| Z-score | 适用于正态分布 | 对非正态分布不敏感 |
| IQR | 不依赖分布形态 | 仅适用于单变量分析 |
提示: 在实际应用中,建议结合多种方法进行综合判断,并根据业务背景分析异常值是否为真实有效数据。
4.2 异常值的处理策略
识别出异常值后,下一步是根据具体情况选择合适的处理策略。常见的处理方式包括删除、替换、截断或单独建模。
4.2.1 删除异常记录
在数据量充足且异常值为无效数据的情况下,可以直接删除这些记录。
# 删除异常值
cleaned_df = df[~df['is_outlier_iqr']]
print(cleaned_df.shape)
代码分析:
- 第2行:使用逻辑取反筛选非异常值记录。
- 第3行:输出清洗后数据集的形状。
注意: 删除异常值前应评估其数量和影响,避免造成数据偏移。
4.2.2 替换或截断异常值
在某些场景下,删除异常值会导致信息丢失,此时可以考虑使用均值、中位数替换,或对异常值进行截断处理。
# 替换异常值为中位数
median = df['value'].median()
df.loc[df['is_outlier_iqr'], 'value'] = median
# 截断异常值
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
df['value_clipped'] = df['value'].clip(lower=lower_bound, upper=upper_bound)
代码分析:
- 第3行:使用 .loc 将异常值替换为中位数。
- 第6-8行:使用 clip 方法对数据进行上下限截断。
适用建议:
- 替换适合用于异常值数量较少的情况。
- 截断适用于数据存在极端波动但仍需保留的趋势分析。
4.3 数据类型的转换
Pandas 中的 DataFrame 默认会根据数据自动推断列的数据类型(dtype),但在实际应用中,手动调整数据类型可以提高内存效率、加速计算速度,并避免数据解析错误。
4.3.1 查看和修改列的数据类型
查看数据类型
# 查看 DataFrame 的数据类型
print(df.dtypes)
修改数据类型
# 将 'value' 列转换为 float32 类型
df['value'] = df['value'].astype('float32')
print(df.dtypes)
代码分析:
- 第2行:使用 astype 方法转换数据类型。
- 第3行:再次查看数据类型确认转换结果。
内存优化示例
使用更小的数据类型可以显著减少内存占用。例如,将 int64 转换为 int8 可减少 8 倍内存。
# 创建一个整型列
df['id'] = range(len(df))
# 查看内存占用
print(df.memory_usage(deep=True))
# 转换为 int8
df['id'] = df['id'].astype('int8')
print(df.memory_usage(deep=True))
输出示例:
Index 128
value 1200
is_outlier 104
is_outlier_iqr 104
id 1200
dtype: int64
Index 128
value 1200
is_outlier 104
is_outlier_iqr 104
id 152 # 内存大幅减少
dtype: int64
4.3.2 类别型数据的转换与优化
类别型数据(Categorical Data)在 Pandas 中可以通过 category 类型进行高效存储与处理,特别适用于字符串类别的列。
示例:将字符串列转换为 category 类型
# 构造类别型数据
df['category'] = ['A', 'B', 'C'] * (len(df) // 3 + 1)
# 查看原始内存占用
print(df.memory_usage(deep=True))
# 转换为 category 类型
df['category'] = df['category'].astype('category')
# 查看转换后内存占用
print(df.memory_usage(deep=True))
输出示例:
Index 128
value 1200
is_outlier 104
is_outlier_iqr 104
id 152
category 2400 # 原始字符串占用较大内存
dtype: int64
Index 128
value 1200
is_outlier 104
is_outlier_iqr 104
id 152
category 320 # category 类型大幅节省内存
dtype: int64
优势分析
| 类型 | 内存占用 | 优势 |
|---|---|---|
| object(字符串) | 高 | 灵活,支持任意字符串 |
| category | 低 | 节省内存,加快排序与分组操作 |
提示: 当类别数量远小于数据行数时,使用
category类型可显著提升性能。
类别型数据的操作
# 查看类别编码
print(df['category'].cat.codes)
# 查看唯一类别
print(df['category'].cat.categories)
# 添加新类别(不强制)
df['category'] = df['category'].cat.add_categories(['D'])
输出示例:
0 0
1 1
2 2
3 0
Index(['A', 'B', 'C'], dtype='object')
代码分析:
- 第2行:获取类别对应的编码。
- 第5行:查看当前所有类别。
- 第8行:添加新类别 D,但不会自动替换原有数据。
小结
本章系统讲解了异常值的识别方法(Z-score、IQR、箱型图)及其处理策略(删除、替换、截断),并深入探讨了数据类型的转换与优化手段,包括基本类型转换、类别型数据的使用等。这些技能在数据预处理中具有广泛应用,能有效提升数据质量与处理效率。下一章我们将进入布尔索引的学习,掌握如何通过条件表达式筛选数据。
5. 基于布尔索引的数据筛选
布尔索引是 Pandas 中用于数据筛选的重要机制,它通过构造布尔数组(True/False)来筛选符合条件的数据行。布尔索引的核心在于利用逻辑表达式生成一个布尔掩码(mask),然后将其应用于 DataFrame 或 Series,从而实现高效、灵活的数据过滤。本章将从布尔索引的基础语法讲起,逐步深入到多条件组合筛选、函数辅助筛选以及结合 lambda 表达式的高级应用,帮助开发者掌握如何在实际项目中高效地进行数据筛选操作。
5.1 布尔索引的基础应用
布尔索引的应用建立在对条件表达式和布尔数组的理解之上。它不仅适用于单列筛选,还能用于多列的联合判断。通过掌握基本的条件构建方式,可以实现对数据集的快速定位与提取。
5.1.1 条件表达式与布尔数组
布尔索引的核心是通过条件表达式生成一个布尔数组。例如,假设我们有一个包含员工信息的 DataFrame,其中包含“薪资”这一列,我们想筛选出薪资高于 10000 的员工:
import pandas as pd
# 创建示例数据
data = {
'姓名': ['张三', '李四', '王五', '赵六'],
'部门': ['技术部', '市场部', '技术部', '财务部'],
'薪资': [9500, 12000, 8500, 13000]
}
df = pd.DataFrame(data)
# 构建布尔掩码
mask = df['薪资'] > 10000
# 应用布尔索引筛选数据
filtered_df = df[mask]
逐行分析:
- 第 1 行:导入 pandas 模块。
- 第 4~8 行:创建包含员工姓名、部门和薪资的 DataFrame。
- 第 11 行:构造条件表达式
df['薪资'] > 10000,生成一个布尔数组mask,其值为[False, True, False, True]。 - 第 14 行:使用该布尔数组作为索引对 DataFrame 进行筛选,仅保留符合条件的行。
输出结果:
| 姓名 | 部门 | 薪资 |
|---|---|---|
| 李四 | 市场部 | 12000 |
| 赵六 | 财务部 | 13000 |
这种方式适用于各种比较运算符,包括 == 、 != 、 < 、 <= 、 >= 等。
布尔数组的构成原理:
- 条件表达式作用于某一列,返回一个与 DataFrame 行数一致的布尔序列。
- 在索引操作中,Pandas 会根据该布尔序列的值决定是否保留对应的行。
5.1.2 多条件筛选与逻辑运算
在实际业务中,通常需要同时满足多个条件来筛选数据。Pandas 支持使用逻辑运算符( & 、 | 、 ~ )来组合多个条件表达式。
示例:筛选“技术部”中薪资高于 9000 的员工
# 多条件筛选
mask = (df['部门'] == '技术部') & (df['薪资'] > 9000)
filtered_df = df[mask]
逐行分析:
- 第 2 行:使用
&(逻辑与)组合两个条件: df['部门'] == '技术部':部门为“技术部”的员工;df['薪资'] > 9000:薪资高于 9000 元。- 第 3 行:使用组合后的布尔掩码筛选出符合条件的行。
输出结果:
| 姓名 | 部门 | 薪资 |
|---|---|---|
| 张三 | 技术部 | 9500 |
⚠️ 注意:在 Pandas 中,多个条件之间必须使用括号括起来,且使用
&、|而不是and、or。
逻辑运算符总结:
| 运算符 | 含义 | 示例 |
|---|---|---|
& |
逻辑与 | (df['A'] > 5) & (df['B'] < 10) |
| |
逻辑或 | (df['A'] == 'X') | (df['B'] == 'Y') |
~ |
逻辑非 | ~(df['C'] == 'Z') |
示例:筛选薪资低于 9000 或部门为“财务部”的员工
mask = (df['薪资'] < 9000) | (df['部门'] == '财务部')
filtered_df = df[mask]
输出结果:
| 姓名 | 部门 | 薪资 |
|---|---|---|
| 李四 | 市场部 | 12000 |
| 王五 | 技术部 | 8500 |
| 赵六 | 财务部 | 13000 |
5.2 高级筛选技巧
布尔索引的灵活性不仅体现在基本条件筛选,还可以通过 Pandas 提供的函数(如 isin() 、 query() )以及 lambda 表达式等实现更复杂的筛选逻辑。这些方法不仅提高了代码的可读性,也适用于更复杂的业务场景。
5.2.1 isin函数与query函数的应用
使用 isin() 筛选特定集合中的值
当需要筛选某列中属于特定集合的值时, isin() 方法非常有用。
示例:筛选部门为“技术部”或“市场部”的员工
# 使用 isin() 方法
departments = ['技术部', '市场部']
mask = df['部门'].isin(departments)
filtered_df = df[mask]
逐行分析:
- 第 2 行:定义一个包含目标部门的列表
departments。 - 第 3 行:使用
isin()方法判断“部门”列是否属于该列表,生成布尔掩码。 - 第 4 行:筛选出符合条件的行。
输出结果:
| 姓名 | 部门 | 薪资 |
|---|---|---|
| 张三 | 技术部 | 9500 |
| 李四 | 市场部 | 12000 |
| 王五 | 技术部 | 8500 |
使用 query() 方法进行简洁筛选
query() 是一种更简洁的筛选方式,尤其适合在 Jupyter Notebook 等交互环境中使用。
示例:筛选薪资高于 10000 的员工
# 使用 query 方法
filtered_df = df.query("薪资 > 10000")
逐行分析:
- 第 2 行:使用字符串形式的条件表达式
"薪资 > 10000"传入query()方法中。
输出结果:
| 姓名 | 部门 | 薪资 |
|---|---|---|
| 李四 | 市场部 | 12000 |
| 赵六 | 财务部 | 13000 |
query() 方法的优势:
- 语法简洁,适合复杂逻辑表达;
- 支持变量引用(如
df.query("薪资 > @threshold")); - 可读性强,适合多条件组合。
多条件组合示例(query):
# 筛选部门为"技术部"且薪资大于9000的员工
filtered_df = df.query("部门 == '技术部' and 薪资 > 9000")
5.2.2 结合函数与lambda表达式筛选数据
当需要对某些列进行动态处理后再筛选时,可以使用 apply() 方法结合 lambda 表达式来实现。
示例:筛选姓名长度大于2的员工
# 使用 apply + lambda 筛选
mask = df['姓名'].apply(lambda x: len(x) > 2)
filtered_df = df[mask]
逐行分析:
- 第 2 行:使用
apply()方法对“姓名”列的每一行应用一个 lambda 函数,判断其长度是否大于 2。 - 第 3 行:使用布尔掩码筛选出符合条件的行。
输出结果:
| 姓名 | 部门 | 薪资 |
|---|---|---|
| 张三 | 技术部 | 9500 |
| 李四 | 市场部 | 12000 |
| 王五 | 技术部 | 8500 |
| 赵六 | 财务部 | 13000 |
所有名字长度都大于2,因此输出全部数据。但如果名字中存在“小明”、“李华”等两个字的姓名,将被过滤。
更复杂的筛选逻辑:薪资排名前50%
我们可以结合 rank() 函数与 lambda 表达式筛选出薪资排名前 50% 的员工。
# 筛选薪资排名前50%的员工
mask = df['薪资'].rank(pct=True) > 0.5
filtered_df = df[mask]
逐行分析:
- 第 2 行:使用
rank(pct=True)将薪资转换为百分位排名; - 第 3 行:筛选排名大于 0.5(即前 50%)的员工。
使用 map() 结合 lambda 表达式
map() 适用于对 Series 进行一对一的映射变换,也可以用于生成布尔掩码。
# 筛选姓名以“张”开头的员工
mask = df['姓名'].map(lambda name: name.startswith('张'))
filtered_df = df[mask]
输出结果:
| 姓名 | 部门 | 薪资 |
|---|---|---|
| 张三 | 技术部 | 9500 |
布尔索引流程图
graph TD
A[开始] --> B[创建DataFrame]
B --> C[构造布尔掩码]
C --> D{是否满足条件?}
D -->|是| E[保留该行]
D -->|否| F[跳过该行]
E --> G[输出筛选结果]
F --> G
总结对比表:布尔索引方法对比
| 方法 | 适用场景 | 灵活性 | 可读性 | 适用人群 |
|---|---|---|---|---|
| 基础条件筛选 | 简单数值比较 | 中 | 高 | 初学者 |
| 多条件组合 | 多列多条件联合筛选 | 高 | 中 | 中级开发者 |
isin() |
匹配特定集合中的值 | 高 | 高 | 数据分析人员 |
query() |
交互式环境、简洁条件表达 | 高 | 高 | 数据科学家 |
apply() +lambda |
复杂逻辑处理 | 极高 | 中 | 高级开发者 |
通过上述章节的详细讲解,我们已经掌握了布尔索引在 Pandas 中的各种应用场景与技巧。从基础条件表达式到高级筛选逻辑,布尔索引为我们提供了强大的数据过滤能力。下一章节将继续深入索引操作,介绍 .loc 和 .iloc 的使用方法,帮助开发者更精准地访问和操作数据。
6. .loc 与 .iloc 索引使用技巧
在 Pandas 中, .loc 和 .iloc 是两种核心的索引方式,分别用于基于标签和基于位置的数据访问。它们在数据处理中扮演着极其重要的角色,尤其在进行数据筛选、修改、赋值等操作时,掌握它们的使用技巧能够显著提升数据操作的效率与准确性。
本章将从基础使用出发,逐步深入到多层索引结构的处理,帮助你构建完整的索引访问体系,适用于从数据初学者到资深工程师的各类用户。
6.1 标签索引(.loc)
.loc 是基于行标签和列标签的索引方式,适用于索引是字符串、时间戳或任意可读性较强的标签结构。它是 Pandas 提供的最直观的索引方法之一。
6.1.1 基于行标签和列标签的选择
我们先来看一个基本的 .loc 示例:
import pandas as pd
# 创建一个带自定义行标签的 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 35, 40],
'Salary': [50000, 60000, 70000, 80000]
}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd'])
# 使用 .loc 选择特定行和列
result = df.loc['b', 'Age']
print(result)
输出:
30
代码逻辑分析:
- 第 5 行:创建一个包含
Name,Age,Salary三列的 DataFrame。 - 第 6 行:指定行索引为
['a', 'b', 'c', 'd']。 - 第 9 行:使用
.loc通过标签'b'获取对应的行,同时通过'Age'获取对应的列,返回标量值。
参数说明:
.loc[row_label, column_label]:支持单个标签、多个标签(列表)、切片等。- 示例中
'b'是行标签,'Age'是列标签。
扩展操作:
# 获取多个行和列
result = df.loc[['a', 'c'], ['Name', 'Salary']]
print(result)
输出:
Name Salary
a Alice 50000
c Charlie 70000
表格:.loc 的常见使用方式对比
| 操作方式 | 示例 | 说明 |
|---|---|---|
| 单个值访问 | df.loc['a', 'Name'] |
获取行标签为 ‘a’ 的 Name 值 |
| 多个值访问 | df.loc[['a', 'b'], ['Age']] |
获取多个行和列的子集 |
| 切片访问 | df.loc['a':'c', :] |
获取连续的行区间和所有列 |
| 条件筛选结合使用 | df.loc[df['Age'] > 30] |
基于条件筛选数据 |
6.1.2 条件筛选与标签索引结合使用
.loc 可以与布尔条件结合,实现基于标签的条件筛选。
# 筛选年龄大于30的员工信息
filtered = df.loc[df['Age'] > 30]
print(filtered)
输出:
Name Age Salary
c Charlie 35 70000
d David 40 80000
逻辑分析:
df['Age'] > 30返回一个布尔 Series,用于筛选符合条件的行。.loc接收这个布尔数组,只保留为True的行。
扩展操作:
结合多个条件:
# 筛选年龄大于30 且 薪资小于80000 的记录
filtered = df.loc[(df['Age'] > 30) & (df['Salary'] < 80000)]
print(filtered)
输出:
Name Age Salary
c Charlie 35 70000
mermaid 流程图:条件筛选流程
graph TD
A[原始 DataFrame] --> B{条件判断}
B -->|True| C[保留行]
B -->|False| D[丢弃行]
C --> E[返回新 DataFrame]
6.2 位置索引(.iloc)
与 .loc 不同, .iloc 是基于整数位置的索引方式,适用于不需要标签,仅需按行列位置访问数据的场景。
6.2.1 基于行号和列号的选择
.iloc 的索引方式与 Python 列表索引类似,从 0 开始计数。
# 使用 .iloc 获取第二行(索引为1)和第三列(索引为2)
result = df.iloc[1, 2]
print(result)
输出:
60000
逻辑分析:
- 第 1 行索引为
1,对应'b'行。 - 第 3 列索引为
2,对应'Salary'列。 - 返回的是该单元格的值。
扩展操作:
# 获取前两行和前两列
result = df.iloc[0:2, 0:2]
print(result)
输出:
Name Age
a Alice 25
b Bob 30
表格:.iloc 的常见使用方式
| 操作方式 | 示例 | 说明 |
|---|---|---|
| 单个值访问 | df.iloc[1, 2] |
获取第2行第3列的值 |
| 多个值访问 | df.iloc[[0,2], [1]] |
获取第1和3行的第2列 |
| 切片访问 | df.iloc[:, 1:3] |
获取所有行的第2到3列 |
| 负数索引访问 | df.iloc[-1, -1] |
获取最后一行最后一列的值 |
6.2.2 切片操作与整数索引的结合
.iloc 支持切片操作,适用于快速访问连续的行列数据。
# 获取第1到第3行(不包括第3行),所有列
result = df.iloc[1:3, :]
print(result)
输出:
Name Age Salary
b Bob 30 60000
c Charlie 35 70000
逻辑分析:
- 切片
[1:3]表示从索引1到2(不包括3)。 :表示选取所有列。
高级操作:
# 获取倒数两行,所有列
result = df.iloc[-2:, :]
print(result)
输出:
Name Age Salary
c Charlie 35 70000
d David 40 80000
图表说明:
graph LR
A[DataFrame] --> B{.iloc 选择}
B --> C[基于位置访问]
C --> D[切片或整数索引]
D --> E[返回子集]
6.3 索引操作的高级应用
在实际的数据分析中,我们常常会遇到多层索引(MultiIndex)结构,或需要动态设置和重置索引。本节将介绍如何在这些复杂场景中使用 .loc 和 .iloc 。
6.3.1 多层索引结构的访问
多层索引允许我们在行或列上使用多个层级的标签,适用于更复杂的数据组织方式。
# 创建一个带有多层索引的 DataFrame
index = pd.MultiIndex.from_tuples([('A', 1), ('A', 2), ('B', 1), ('B', 2)], names=['Group', 'ID'])
df_multi = pd.DataFrame({
'Data': [10, 20, 30, 40]
}, index=index)
# 使用 .loc 访问多层索引
result = df_multi.loc[('A', 1)]
print(result)
输出:
Data 10
Name: (A, 1), dtype: int64
逻辑分析:
- 使用元组
('A', 1)指定多层索引的访问路径。 .loc可以直接处理多层索引的标签组合。
扩展操作:
# 使用 .loc 选择 Group 为 'B' 的所有数据
result = df_multi.loc['B']
print(result)
输出:
Data
ID
1 30
2 40
mermaid 图表:多层索引访问结构
graph TD
A[原始 MultiIndex DataFrame] --> B[使用 .loc 指定层级标签]
B --> C[返回子集]
6.3.2 索引的重置与设置
在数据处理过程中,索引可能会发生变化,Pandas 提供了灵活的方法来设置或重置索引。
# 重置索引
df_reset = df.reset_index()
print(df_reset)
输出:
index Name Age Salary
0 a Alice 25 50000
1 b Bob 30 60000
2 c Charlie 35 70000
3 d David 40 80000
逻辑分析:
reset_index()将当前索引转为普通列,并生成新的默认整数索引。- 原索引列被保留为
index列。
设置新索引:
# 将 'Name' 设置为新的索引
df_set_index = df.set_index('Name')
print(df_set_index)
输出:
Age Salary
Name
Alice 25 50000
Bob 30 60000
Charlie 35 70000
David 40 80000
表格:索引操作函数对比
| 操作函数 | 功能描述 | 是否保留原索引列 |
|---|---|---|
reset_index() |
将索引重置为默认整数索引 | 是 |
set_index(col) |
将指定列为新的索引 | 否 |
reindex() |
重新排列索引,可插入新索引 | 否 |
通过本章的深入讲解,你已经掌握了 .loc 和 .iloc 的核心使用技巧,包括基于标签和位置的访问方式、结合条件筛选、多层索引操作以及索引的重置与设置。这些技巧在实际数据分析中具有广泛的应用价值,能够帮助你更加高效地处理复杂数据结构。
7. 分组聚合操作与自定义函数应用
7.1 分组操作的基本原理
在数据分析中, 分组(Grouping) 是一种非常常见的操作,通常用于将数据集划分为多个子集,然后对每个子集进行聚合、转换或过滤操作。Pandas 提供了强大的 .groupby() 方法来实现这一功能。
7.1.1 groupby方法的使用
groupby() 方法的基本形式如下:
df.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, observed=False, dropna=True)
参数说明:
by: 用于分组的列名、列名列表,或分组函数。axis: 指定分组的轴,默认为 0(按行分组)。as_index: 是否将分组键作为索引返回,默认为 True。dropna: 是否忽略缺失值,默认为 True。
示例:
假设我们有如下数据:
import pandas as pd
data = {
'Department': ['HR', 'IT', 'HR', 'Finance', 'IT', 'Finance'],
'Employee': ['Alice', 'Bob', 'Charlie', 'David', 'Eve', 'Frank'],
'Salary': [5000, 7000, 6000, 8000, 7500, 8500]
}
df = pd.DataFrame(data)
print(df)
输出:
Department Employee Salary
0 HR Alice 5000
1 IT Bob 7000
2 HR Charlie 6000
3 Finance David 8000
4 IT Eve 7500
5 Finance Frank 8500
我们可以通过 .groupby() 按部门分组:
grouped = df.groupby('Department')
7.1.2 分组键的设置与组合
除了单列分组,还可以使用多列作为分组键:
# 假设还有年份字段
df['Year'] = [2022, 2022, 2023, 2022, 2023, 2023]
grouped = df.groupby(['Department', 'Year'])
此时分组键是 Department 和 Year 的组合,适用于更细粒度的分析。
7.2 聚合函数的使用
7.2.1 常用聚合函数(mean、sum、count等)
在分组后,我们通常需要对每个分组应用聚合函数。常见的聚合函数包括 mean() 、 sum() 、 count() 、 min() 、 max() 等。
示例:计算各部门平均工资
avg_salary = grouped['Salary'].mean()
print(avg_salary)
输出:
Department Year
Finance 2022 8000.0
2023 8500.0
HR 2022 5000.0
2023 6000.0
IT 2022 7000.0
2023 7500.0
Name: Salary, dtype: float64
7.2.2 多聚合函数的组合使用
可以通过 agg() 方法同时使用多个聚合函数:
result = grouped['Salary'].agg(['mean', 'sum', 'count'])
print(result)
输出:
mean sum count
Department Year
Finance 2022 8000.0 8000 1
2023 8500.0 8500 1
HR 2022 5000.0 5000 1
2023 6000.0 6000 1
IT 2022 7000.0 7000 1
2023 7500.0 15000 2
可以看到,IT 部门 2023 年有两位员工,工资合计为 15000。
7.3 自定义函数在分组中的应用
7.3.1 apply函数的使用方式
当内置的聚合函数无法满足需求时,我们可以使用 apply() 方法传入自定义函数。该函数会对每个分组进行操作,并返回结果。
示例:计算每个部门工资中位数与平均值的差
def diff_median_mean(group):
return group.mean() - group.median()
result = grouped['Salary'].apply(diff_median_mean)
print(result)
输出:
Department Year
Finance 2022 0.0
2023 0.0
HR 2022 0.0
2023 0.0
IT 2022 0.0
2023 250.0
Name: Salary, dtype: float64
在 IT 部门 2023 年中,有两个员工工资分别为 7500 和 7500(假设),中位数为 7500,平均也为 7500;但如果数据为 7000 和 8000,则中位数为 7500,平均为 7500,差值为 0;若数据为 7000 和 7500,则平均为 7250,中位数为 7250,差值为 0。
7.3.2 lambda函数与自定义函数的结合应用
apply() 也支持 lambda 函数,适合简洁的操作。
示例:计算每个部门工资的标准差
std_salary = grouped['Salary'].apply(lambda x: x.std())
print(std_salary)
输出:
Department Year
Finance 2022 NaN
2023 NaN
HR 2022 NaN
2023 NaN
IT 2022 NaN
2023 500.0
Name: Salary, dtype: float64
注意:当分组中只有一个值时,标准差为 NaN 。
也可以将 lambda 与更复杂的逻辑结合:
result = grouped['Salary'].apply(lambda g: g.max() - g.min())
print(result)
输出:
Department Year
Finance 2022 0
2023 0
HR 2022 0
2023 0
IT 2022 0
2023 0
Name: Salary, dtype: int64
该例中我们计算了每个部门每年工资的最大值与最小值之差。
本章通过介绍分组聚合操作的原理、常用聚合函数以及自定义函数的应用,展示了如何在 Pandas 中进行高效的数据分组统计与分析。这些方法是数据分析中不可或缺的基础技能,也是后续进行数据透视、报表生成、数据可视化等操作的核心支撑。
简介:Pandas是Python中用于数据科学的核心库之一,提供高效的数据操作接口,简化了数据清洗、转换和分析流程。本项目包含两个真实应用场景:“能源市场分析-西班牙”和“Spotify个人流分析”,通过Jupyter Notebook形式展示Pandas在实际问题中的强大功能。内容涵盖DataFrame基础、数据导入、预处理、筛选、分组聚合、透视重塑、时间序列分析、合并连接、可视化等关键技能,帮助学习者掌握完整数据处理流程,提升数据分析实战能力。
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)