
怎样使用pandas的分层索引MultiIndex
怎样使用pandas的分层索引MultiIndex
·
为什么要使用分层索引MultiIndex
- 分层索引:在一个轴向上拥有多个索引层级,可以表达更高维度数据的形式。
- 可以更方便的进行数据筛选,如果索引有序则性能更好。
- groupby等操作的结果,如果是根据多个key分组,结果是分层索引。
实例
数据准备
数据来源于 英为财情:https://cn.investing.com/
例如,搜索京东的股票:
点击进入:
找到下面的 历史数据,然后点击:
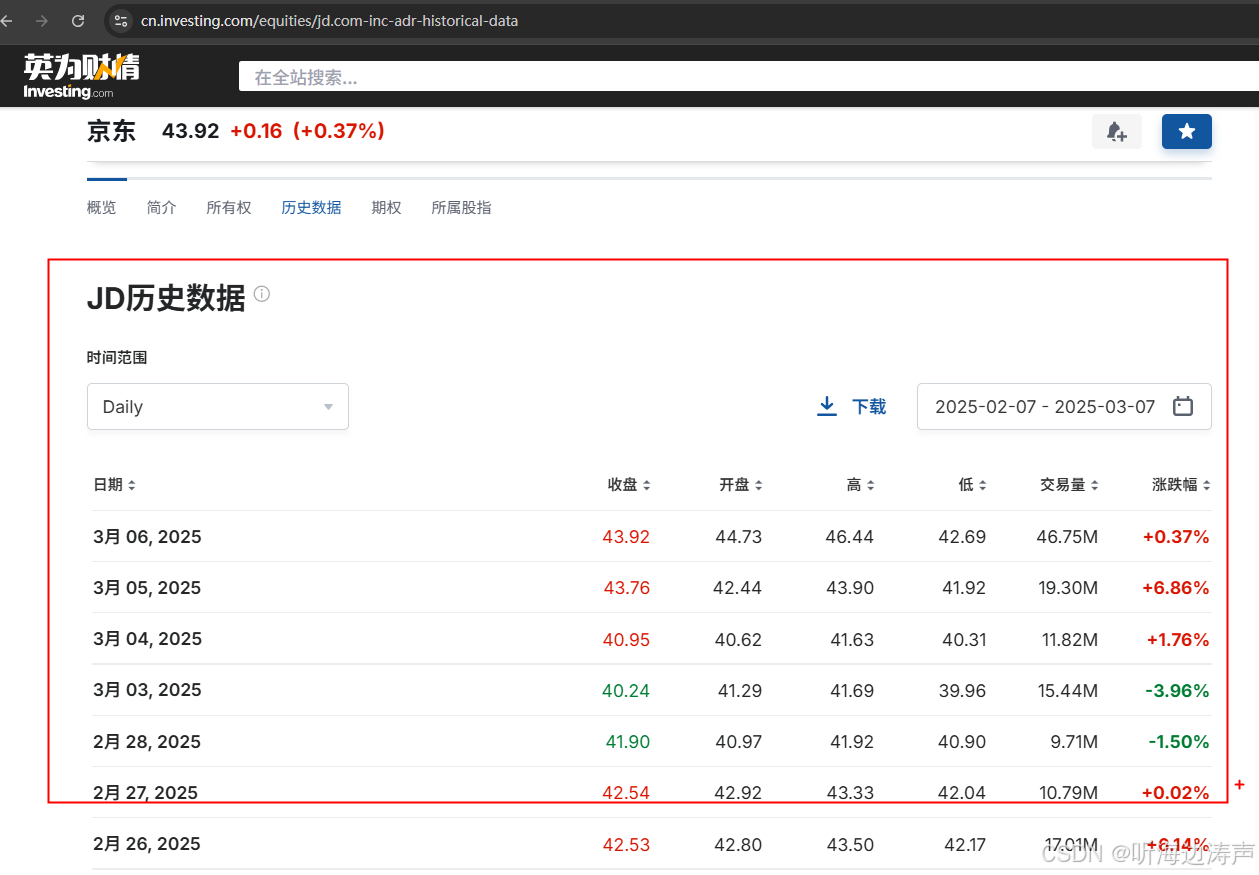
就可以将数据拷贝到excel中。
找了4个公司的股票,每个公司3天,增加 公司 这列,汇总到一起,最后excel文件中的内容如下: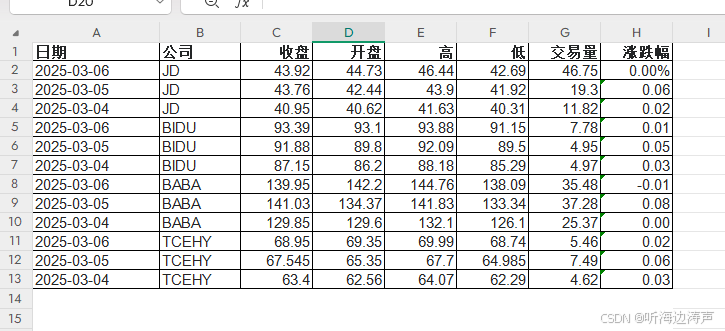
读取excel中的数据,转换为DataFrame:
import pandas as pd
stock_df = pd.read_excel('./data/几家公司几天的股票.xlsx')
查看DataFrame: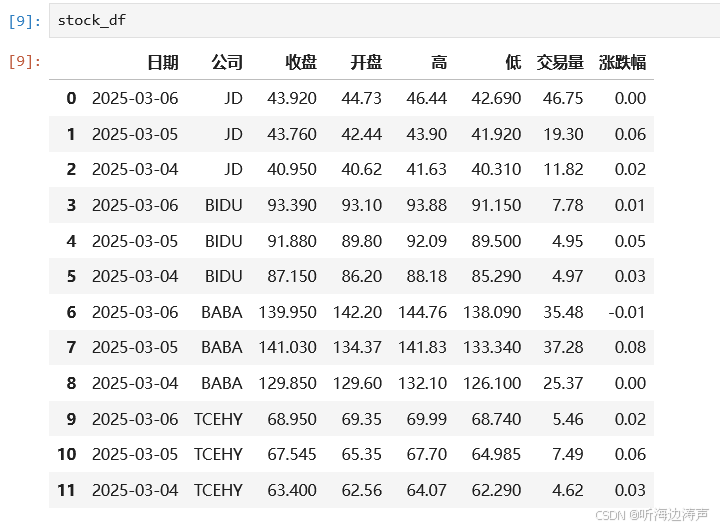
查看数据的形状:
查看包含哪些公司:
查看数据的索引: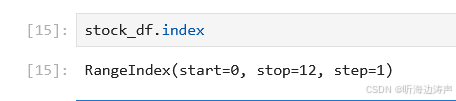
对公司进行分组,然后看收盘的平均值:
Series的分层索引MultiIndex
按照公司、日期进行分组聚合:
ser = stock_df.groupby(['公司', '日期'])['收盘'].mean()
查看返回值的类型,是一个Series: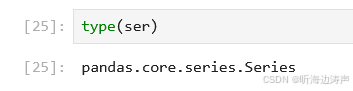
查看Series的内容: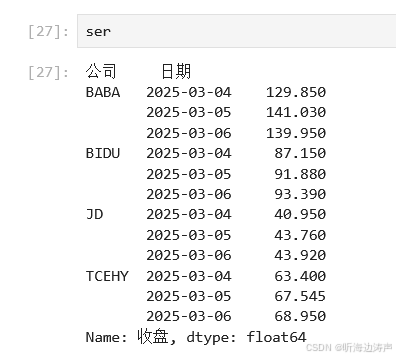
上面结果中,公司和日期构成了多维索引。在多维索引中,空白的意思表示使用上面的值。例如BABA下面两行公司的地方是空白,表示使用BABA。
查看下Series的索引:
unstack把第二级索引变成列: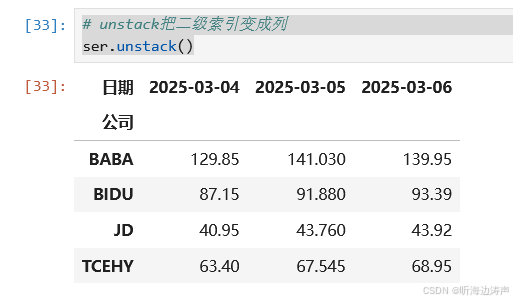
重新查看下ser: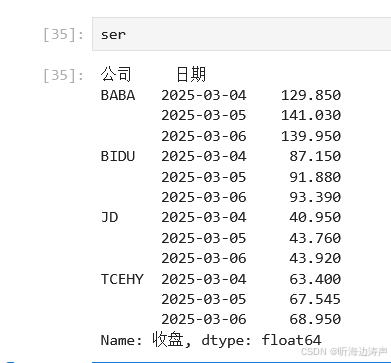
把索引变成列: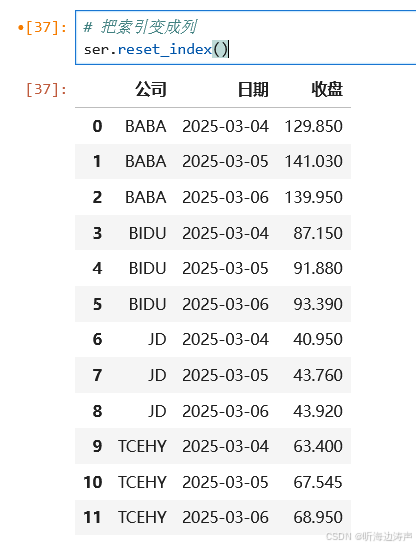
当Series有多层索引MultiIndex时,如何筛选数据
先看看Series: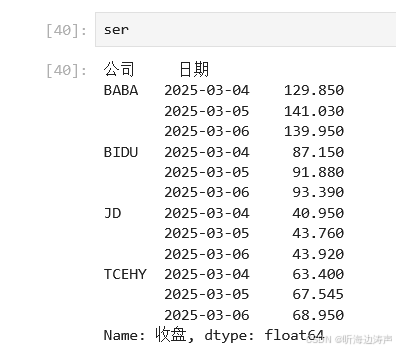
筛选某个公司的数据:
用多层索引筛选数据,可以用元组的形式筛选:
如果只筛选第二级索引,可以把第一级索引写成冒号(: 表示全部):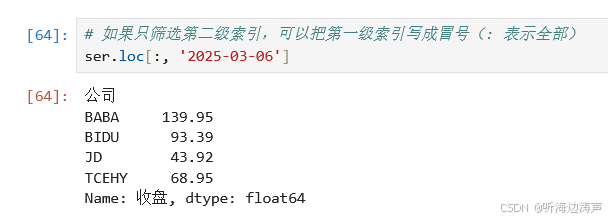
DataFrame的多层索引MultiIndex
先看下原始的DataFrame: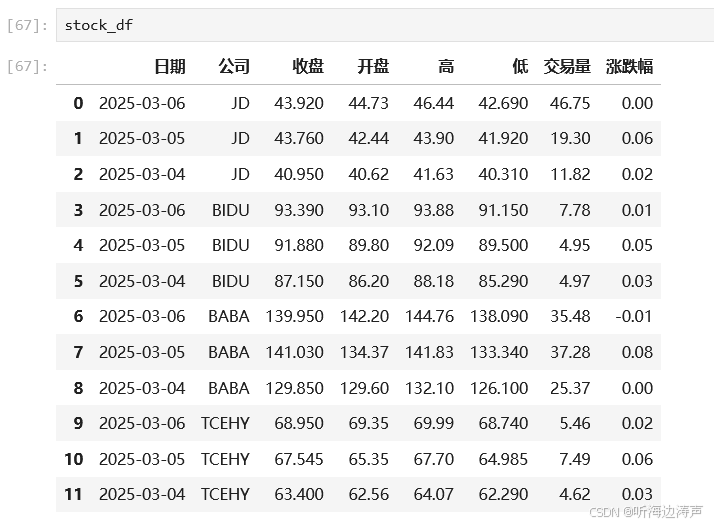
设置分层索引:
stock_df.set_index(['公司', '日期'], inplace=True)
查看结果: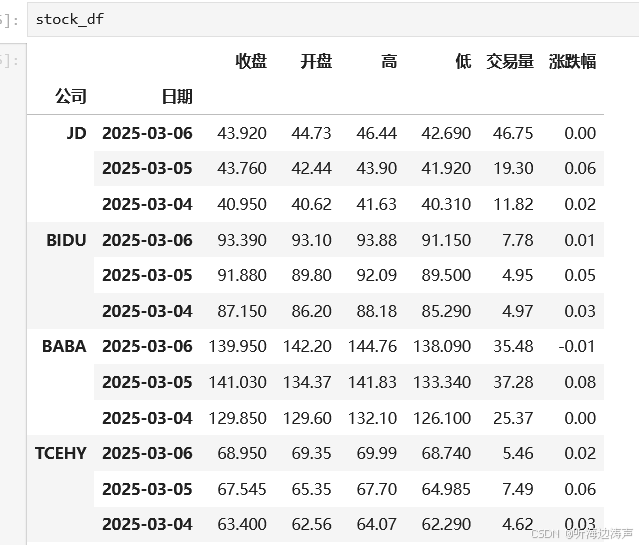
查看下索引: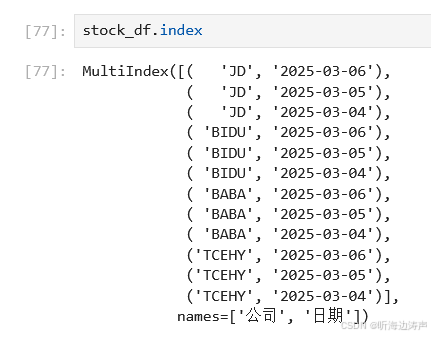
将索引排序:
# 将索引排序
stock_df.sort_index(inplace=True)
查看下结果: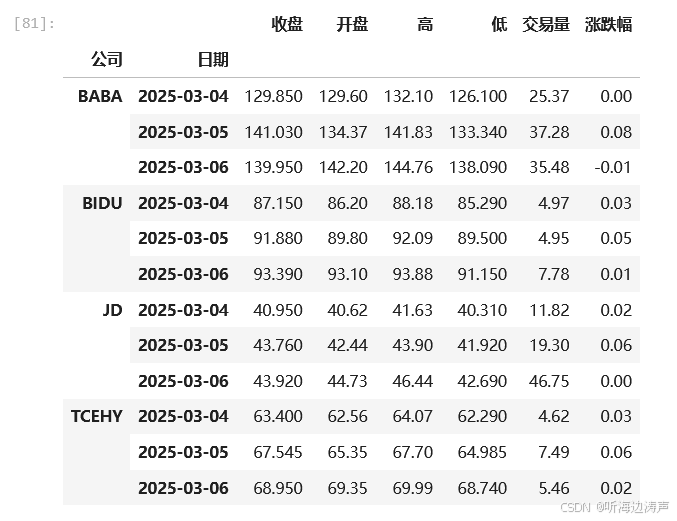
当DataFrame有多层索引MultiIndex时,如何筛选数据
注意,在选择数据时:
- 元组
(key1, key2)代表筛选多层索引,其中key1是索引的第一级,key2是索引的第二级,例如key1传入公司名称,key2传入日期。 - 列表
[key1, key2]代表筛选同一个层级的多个key,其中key1和key2是并列的同级索引,例如key1传入公司1的名称,key2传入公司2的名称。
先看下DataFrame: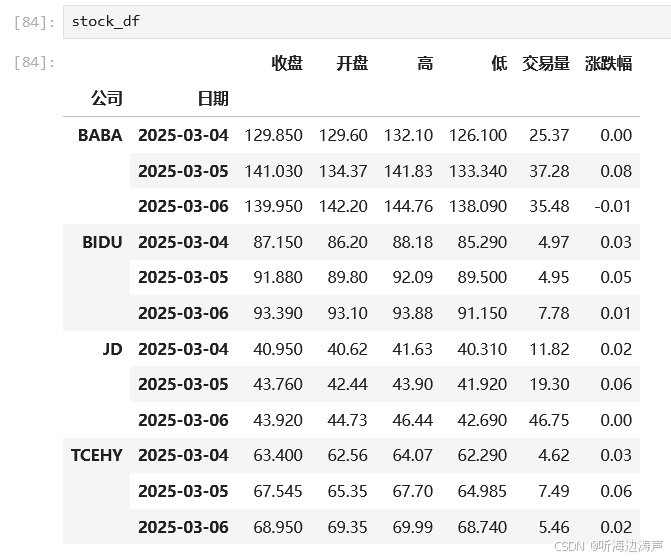
筛选第一层索引: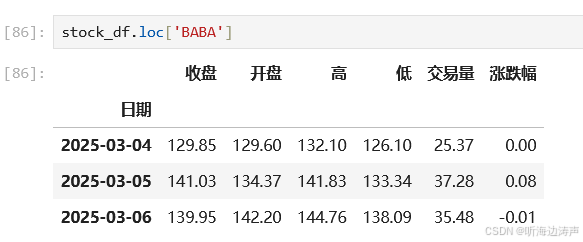
根据多级索引查询:
根据多级索引查询,只查询一列:
根据第一级索引的多个值筛选: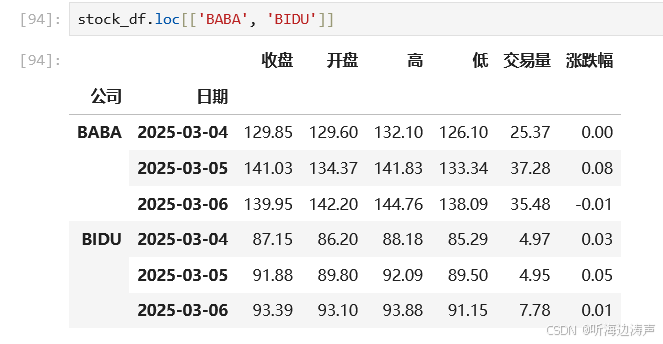
第一级索引传入多个值,第二级索引传入1个值,筛选所有列: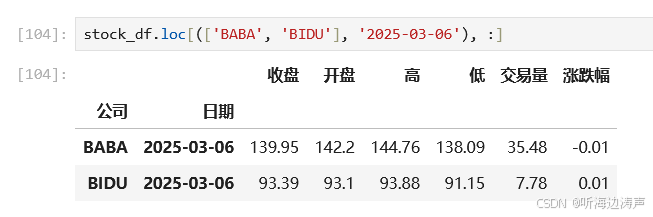
第一级索引传入多个值,第二级索引传入1个值,筛选1列: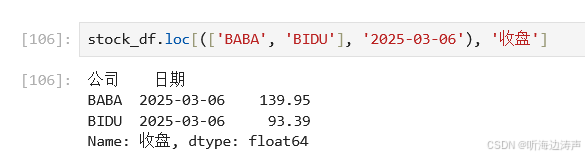
第一级索引传入1个值,第二级索引传入多个值,筛选1列: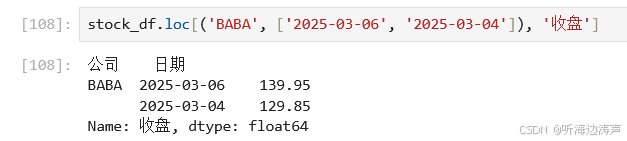
slice(None)代表这一索引的所有内容: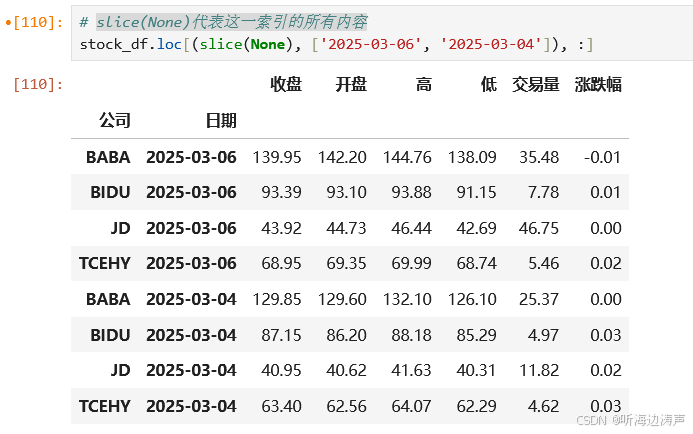
reset_index()把多级索引变为列: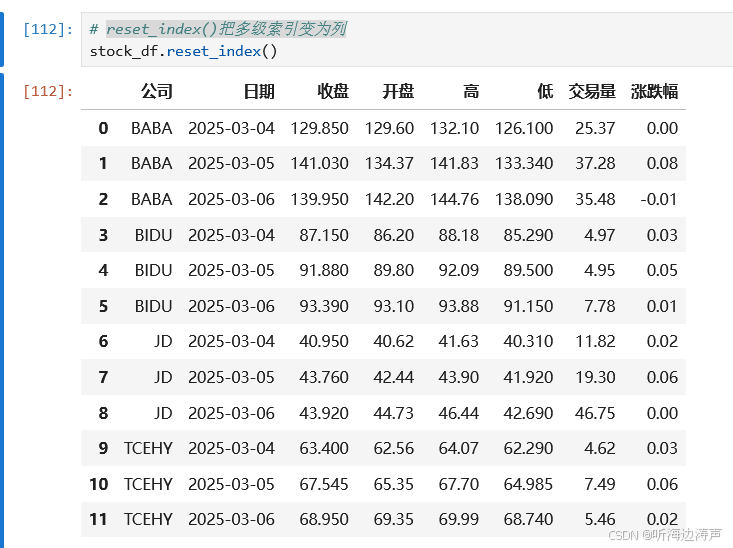
更多推荐



 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)